În ultimii ani, testarea automată a devenit o tendință în dezvoltarea de software, într-un fel, implementarea sa a devenit un „tribut adus modei”. Cu toate acestea, implementarea și întreținerea testelor automate este o procedură care necesită foarte mult resurse și, prin urmare, nu este ieftină. Utilizarea pe scară largă a acestui instrument duce cel mai adesea la pierderi financiare semnificative fără niciun rezultat semnificativ.
Cum puteți folosi un instrument destul de simplu pentru a evalua posibila eficiență a utilizării autotestelor pe un proiect?
Ce este definit ca „eficacitatea” automatizării testelor?
Cel mai comun mod de a evalua eficiența (în primul rând economic) este calculul randamentului investiției(ROI). Se calculează destul de simplu, fiind raportul dintre profit și costuri. De îndată ce valoarea ROI trece peste unu, soluția returnează fondurile investite în ea și începe să aducă altele noi.
În cazul automatizării, profit înseamnă economisirea testării manuale... În plus, profitul în acest caz poate să nu fie evident - de exemplu, rezultatele găsirii defectelor în procesul de testare ad-hoc de către ingineri, al căror timp a fost eliberat din cauza automatizării. Un astfel de profit este destul de dificil de calculat, așa că puteți fie să faceți o presupunere (de exemplu + 10%), fie să o omiteți.
Cu toate acestea, economiile nu sunt întotdeauna scopul implementării automatizării. Un exemplu este viteza de executare a testului(atât în ceea ce privește viteza de execuție a unui singur test, cât și în ceea ce privește frecvența testării). Din mai multe motive, viteza de testare poate fi critică pentru o afacere - dacă investiția în automatizare plătește profiturile rezultate.
Alt exemplu - excluderea „factorului uman” din procesul de testare a sistemului. Acest lucru este important atunci când acuratețea și corectitudinea operațiunilor sunt esențiale pentru afacere. Costul unei astfel de erori poate fi semnificativ mai mare decât costul dezvoltării și menținerii unui autotest.
De ce să măsori performanța?
Măsurarea eficienței ajută la răspunsul la întrebările: „Merită implementarea automatizării pe proiect?”, „Când ne va aduce implementarea un rezultat semnificativ?” „Câte ore de testare manuală vom înlocui?”? si etc.
Aceste calcule pot ajuta la formularea obiectivelor (sau a valorilor) pentru echipa de automatizare a testelor. De exemplu, economisind X ore pe lună de testare manuală, reducând costul unei echipe de testare cu Y unități convenționale.
De fiecare dată când eșuăm o altă lansare, începe o forfotă. Imediat apar vinovații și de multe ori suntem noi, testerii. Poate că destinul este ultima verigă din ciclul de viață al software-ului, așa că, chiar dacă un dezvoltator petrece mult timp scriind cod, nimeni nu crede că testarea este și oameni cu anumite capacități.
Nu poți sări deasupra capului, dar poți lucra 10-12 ore. Am auzit foarte des astfel de fraze)))
Când testarea nu satisface nevoile afacerii, atunci se pune întrebarea, de ce testarea, dacă nu au timp să lucreze la timp. Nimeni nu se gândește la ce s-a întâmplat înainte, de ce cerințele nu au fost scrise normal, de ce nu a fost gândită arhitectura, de ce codul este strâmb. Dar când aveți un termen limită și nu aveți timp să finalizați testarea, atunci încep imediat să vă pedepsească...
Dar acestea au fost câteva cuvinte despre viața grea a unui tester. Acum la obiect 🙂
După câteva astfel de falsuri, toată lumea începe să se întrebe ce este greșit în procesul nostru de testare. Poate că tu, ca lider, înțelegi problemele, dar cum le comunici conducerii? Întrebare?
Conducerea are nevoie de cifre, de statistici. Cuvinte simple - te-au ascultat, au clătinat din cap, au spus - „Hai, fă-o” și atât. După aceea, toată lumea așteaptă un miracol de la tine, dar chiar dacă ai făcut ceva și nu ai reușit, tu sau liderul tău primești din nou o pălărie.
Orice schimbare trebuie susținută de management, iar pentru ca managementul să o susțină, au nevoie de cifre, măsurători, statistici.
De multe ori am văzut cum au încercat să descarce diverse statistici din instrumentele de urmărire a sarcinilor, spunând că „Eliminăm valorile din JIRA”. Dar să vedem ce este o metrică.
Metrica este o mărime măsurabilă din punct de vedere tehnic sau procedural care caracterizează starea unui obiect controlat.
Să vedem - echipa noastră descoperă 50 de defecte în timpul testării de acceptare. E mult? Sau putin? Vă spun aceste 50 de defecte despre starea obiectului de control, în special despre procesul de testare?
Probabil ca nu.
Și dacă ți s-a spus că numărul de defecte găsite în timpul testării de acceptare este de 80%, în timp ce acesta ar trebui să fie de doar 60%. Cred că este imediat clar că există o mulțime de defecte, respectiv, ca să spunem ușor, codul dezvoltatorilor este plin de g... .. nesatisfăcător din punct de vedere calitativ.
Cineva ar putea spune că de ce să testăm atunci? Dar voi spune că defectele sunt timpul de testare, iar timpul de testare este ceea ce ne afectează direct termenul limită.
Prin urmare, nu avem nevoie doar de metrici, avem nevoie de KPI-uri.
KPI este o metrică care servește ca indicator al stării obiectului de control. O condiție prealabilă este prezența unei valori țintă și a toleranțelor stabilite.
Adică, întotdeauna, atunci când construiești un sistem de metrici, trebuie să ai un obiectiv și abateri acceptabile.
De exemplu, aveți nevoie (scopul dvs.) ca 90% din toate defectele să fie rezolvate de la prima iterație. În același timp, înțelegeți că acest lucru nu este întotdeauna posibil, dar chiar dacă numărul de defecte rezolvate prima dată este egal cu 70%, este și acest lucru bun.
Adică ți-ai stabilit un obiectiv și o marjă de eroare. Acum, dacă numărați defectele din ediție și obțineți o valoare de 86%, atunci acest lucru cu siguranță nu este bine, dar nu mai este un eșec.
Din punct de vedere matematic, va arăta astfel:
De ce 2 formule? Acest lucru se datorează faptului că există un concept de metrici de jos în sus și de sus în jos, adică când valoarea noastră țintă se apropie de 100% sau 0%.
Acestea. daca vorbim, de exemplu, de numarul de defecte constatate in urma implementarii in operare industriala, atunci cu cat mai putine cu atat mai bine, iar daca vorbim de acoperirea functionalitatii prin cazuri de testare, atunci totul va fi invers.
În același timp, nu uitați despre cum să calculați aceasta sau acea măsurătoare.
Pentru a obține procentele de care avem nevoie, bucăți etc., trebuie să calculăm fiecare metrică.
Pentru un exemplu ilustrativ, vă voi spune despre metrica „Promptitudinea procesării defectelor prin testare”.
Folosind o abordare similară, pe care am descris-o mai sus, formăm și KPI-ul pentru metrică pe baza valorilor și abaterilor țintă.
Nu vă alarmați, în viață nu este atât de dificil pe cât arată în poză!

Ce avem?
Ei bine, este clar că numărul lansării, numărul incidentului...
Critic - cote. 5,
Major - cote. 3,
Minor - cote. 1.5.
În continuare, trebuie să specificați SLA pentru timpul procesării defectelor. Pentru a face acest lucru, se determină valoarea țintă și timpul maxim admisibil de retestare, în același mod în care am descris-o mai sus pentru calcularea valorilor.
Pentru a răspunde la aceste întrebări, vom trece direct la valoarea performanței și vom pune întrebarea imediat. Și cum se calculează indicatorul, dacă valoarea unei cereri poate fi egală cu „zero”. Dacă unul sau mai mulți indicatori sunt egali cu zero, atunci indicatorul final va scădea foarte puternic, așa că se pune întrebarea cum să echilibrăm calculul nostru, astfel încât valorile zero, de exemplu, ale interogărilor cu un factor de severitate de „1”, nu afectează foarte mult evaluarea noastră finală.
Greutatea- aceasta este valoarea de care avem nevoie pentru ca cererile sa aiba cel mai mic impact asupra notei finale cu un factor de severitate redus, si invers, cererea cu cel mai mare factor de severitate are un impact semnificativ asupra notei, cu conditia sa fim întârziat pentru această cerere.
Pentru a nu avea o neînțelegere în calcule, vom introduce variabile specifice pentru calcul:
x este timpul efectiv petrecut pentru retestarea defectului;
y este abaterea maximă admisă;
z este coeficientul de greutate.
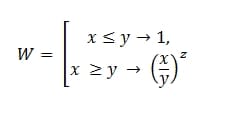
Sau în limba obișnuită, este:
W = ESLI(X<=y,1,(x/y)^z)
Astfel, chiar dacă am depășit cadrul stabilit de SLA, cererea noastră, în funcție de gravitate, nu ne va afecta în mod serios rezultatul final.
Totul este așa cum este descris mai sus:
NS- timpul efectiv petrecut pentru retestarea defectului;
y- abaterea maxima admisa;
z Este coeficientul de gravitație.
h - timpul planificat conform SLA
Nu mai știu să exprim asta într-o formulă matematică, așa că voi scrie în limbaj programatic cu operatorul DACĂ.
R = DACA (x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
În consecință, obținem că, dacă am atins obiectivul, atunci valoarea cererii noastre este 1, dacă am depășit abaterea admisă, atunci ratingul este egal cu zero și ponderile sunt calculate.
Dacă valoarea noastră este între țintă și abaterea maximă admisă, atunci în funcție de coeficientul de greutate, valoarea noastră variază în interval.
Acum voi da câteva exemple despre cum va arăta acest lucru în sistemul nostru de metrici.
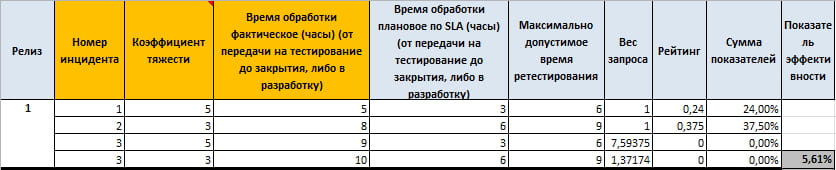
Pentru fiecare cerere, în funcție de importanța lor (coeficient de severitate), există propriul SLA.
Ce vedem aici.
La prima solicitare am deviat doar cu o oră de la valoarea țintă și avem deja un rating de 30%, în timp ce la a doua solicitare am deviat și cu doar o oră, dar suma indicatorilor nu mai este de 30%, ci 42,86%. Adică, factorii de severitate joacă un rol important în formarea indicatorului final de interogare.
Totodată, la a treia cerere, am încălcat timpul maxim admisibil și ratingul este egal cu zero, dar ponderea cererii s-a modificat, ceea ce ne permite să calculăm mai corect influența acestei solicitări asupra coeficientului final.
Ei bine, pentru a fi sigur de acest lucru, puteți calcula pur și simplu că media aritmetică a indicatorilor va fi de 43,21%, iar noi am obținut 33,49%, ceea ce indică un impact serios al interogărilor de mare importanță.
Să modificăm valorile din sistem cu 1 oră.
totodată, pentru a 5-a prioritate, valoarea s-a modificat cu 6%, iar pentru a treia cu 5,36%.
Din nou, importanța interogării afectează valoarea acesteia.

Gata, obținem metrica finală.
Ce este important!
Nu spun că utilizarea unui sistem metric ar trebui făcută prin analogie cu valorile mele, sugerez doar o abordare pentru menținerea și colectarea acestora.
Într-o organizație, am văzut că și-au dezvoltat propriul cadru pentru colectarea de valori de la HP ALM și JIRA. Acest lucru este foarte cool. Dar este important să ne amintim că un astfel de proces de menținere a valorilor necesită o aderență serioasă la procesele de reglementare.
Ei bine, și cel mai important, doar tu poți decide cum și ce valori să colectezi. Nu este nevoie să copiați acele valori pe care nu le puteți colecta.
Abordarea este complexă, dar puternică.
Încearcă și tu s-ar putea să reușești!
Alexander Meshkov, Chief Operations Officer la Performance Lab, are peste 5 ani de experiență în testarea software-ului, managementul testelor și consultanța QA. Expert ISTQB, TPI, TMMI.
Scopul evaluării eficacității, pe care unii au numit-o deja „formula nefericirii”, este de a face testerul fericit, astfel încât să se poată arăta cu cifre că unul funcționează bine și trebuie bătut pe cap, în timp ce celălalt este rău și trebuie biciuit... conform acestui criteriu, nu poate fi singurul, prin urmare ar trebui luat în considerare împreună cu alți indicatori, cum ar fi execuția planului, automatizarea testelor etc.
Performanța unui tester, ca orice alt angajat, trebuie cuantificată, adică. într-un indicator măsurabil. Dar ce valori ar trebui să alegi?
Primul lucru care îmi vine în minte este numărul de defecte găsite. Și acest indicator a fost pe care am încercat imediat să îl introduc în Inreko LAN. Totuși, imediat a apărut o discuție aprinsă, care m-a determinat să analizez acest criteriu. Pe acest subiect vreau să speculez în acest articol.
Numărul de defecte găsite este un indicator extrem de alunecos. Toate resursele din rețea care discută această problemă repetă și ele același lucru (http://www.software-testing.ru/, blogs.msdn.com/imtesty, it4business.ru, sqadotby.blogspot.com, bloguri. msdn.com / larryosterman, sql.ru, http://www.testingperspective.com/ și multe, multe altele). După ce mi-am analizat propria experiență și aceste resurse, am ajuns la următorul arbore de probleme:
În primul rând, există o diferență între un defect și un defect. Un tester poate căuta defecte în aranjarea butoanelor în aplicație, altul - săpa în logică și să vină cu situații complexe de testare. În cele mai multe cazuri, primul tester va găsi mai multe defecte, deoarece chiar și pregătirea testului îi va lua mult mai puțin timp, dar valoarea unor astfel de defecte este mult mai mică. Această problemă este ușor de rezolvat prin introducerea criticității defectului. Se poate aprecia după numărul de defecte găsite în fiecare dintre categorii. De exemplu, avem 4 dintre ele: critice, semnificative, medii și nesemnificative. Dar, deoarece granița definiției criticității nu este complet clară, deși avem semne formale de criticitate, atunci putem merge în două moduri mai sigure. Primul este că o anumită parte a defectelor găsite pentru perioada selectată nu ar trebui să fie defecte critice scăzute. Al doilea este de a ignora defectele minore în evaluare. Astfel, luptam cu dorinta testerului de a colecta cat mai multe defecte prin descrierea defectelor minore, fortandu-l (sau mai des pe ea) sa sape mai adanc si sa gaseasca defecte serioase. Și ei sunt mereu acolo, crede-mi experiența. Am ales a doua opțiune - aruncați defecte minore.
Al doilea motiv pentru „alunecarea” unui astfel de criteriu este prezența unui număr suficient de defecte în sistem pentru ca testatorul să le găsească. Există trei factori aici. Primul este complexitatea logicii și tehnologiei sistemului. Al doilea este calitatea codificării. Iar a treia este etapa de proiect. Să examinăm acești trei factori în ordine. Complexitatea logicii și tehnologiei pe care este scris sistemul afectează potențialele defecte care pot fi făcute. Mai mult decât atât, dependența aici este departe de a fi directă. Dacă implementați o logică simplă pe o platformă complexă sau necunoscută, erorile vor fi legate în principal de utilizarea incorectă a tehnologiei de implementare. Dacă implementați o logică complexă pe o platformă primitivă, atunci, cel mai probabil, erorile vor fi asociate atât cu logica în sine, cât și cu complexitatea implementării unei astfel de logici într-un limbaj primitiv. Adică este nevoie de un echilibru atunci când alegeți o tehnologie pentru implementarea unui sistem. Dar adesea tehnologia este dictată de client sau de piață, așa că cu greu putem influența. Prin urmare, rămâne doar să luăm în considerare acest factor ca un anumit coeficient al numărului potențial de defecte. Mai mult, valoarea acestui coeficient, cel mai probabil, trebuie să fie determinată de experți.
Calitatea codificării. Aici cu siguranță nu putem influența dezvoltatorul în niciun fel. Dar putem: a) să evaluăm din nou cu expertiză nivelul dezvoltatorului și să-l includem ca un alt factor și b) să încercăm să prevenim erorile în cod prin teste unitare, făcând acoperirea codului 100% prin teste unitare o cerință obligatorie.
Etapa proiectului. Se știe de mult că este imposibil să găsești toate defectele, decât pentru un program banal sau accidental, deoarece nu există limită pentru perfecțiune, iar orice necoincidență cu perfecțiunea poate fi considerată un defect. Dar una este atunci când un proiect se află în stadiul activ de dezvoltare și cu totul altceva când se află în faza de suport. Și dacă luăm în considerare și factorii complexității sistemului și tehnologiei și calitatea codificării, atunci este clar că toate acestea afectează radical numărul de defecte pe care un tester este capabil să le găsească. Pe măsură ce proiectul se apropie de finalizare sau de faza de suport (numim totul condiționat și îl definim intuitiv acum), numărul de defecte din sistem scade și, prin urmare, și numărul de defecte găsite. Și aici este necesar să se determine momentul în care devine nerezonabil să se ceară de la tester să găsească un anumit număr de defecte. Pentru a determina un astfel de moment, ar fi bine să știm ce parte din numărul total de defecte putem găsi și câte defecte au mai rămas în sistem. Acesta este un subiect pentru o discuție separată, dar poate fi aplicată o metodă statistică destul de simplă și eficientă.
Pe baza statisticilor proiectelor anterioare, se poate înțelege, cu o anumită marjă de eroare, câte defecte au fost în sistem și câte au fost găsite de echipa de testare în diferite perioade ale proiectului. Astfel, puteți obține un anumit indicator statistic mediu al eficienței echipei de testare. Poate fi descompus pentru fiecare tester individual și poate obține o evaluare personalizată. Cu cât mai multă experiență și statistici, cu atât eroarea va fi mai mică. De asemenea, puteți folosi metoda „sămânțare erori”, când știm exact câte erori sunt în sistem. Desigur, trebuie luați în considerare factori suplimentari, cum ar fi tipul de sistem, complexitatea logicii, platforma etc. Așadar, obținem relația dintre faza de proiect și procentul de defecte constatate. Acum putem aplica această dependență în sens invers: cunoscând numărul de defecte găsite și faza curentă a proiectului, putem determina numărul total de defecte din sistemul nostru (cu o oarecare marjă de eroare, desigur). Și apoi, pe baza indicatorilor de evaluare personală sau generală, puteți determina câte defecte le poate găsi testatorul sau echipa în perioada de timp rămasă. Pe baza acestei evaluări, este deja posibil să se definească un criteriu pentru eficacitatea muncii unui tester.
Funcția de măsurare a performanței testerului ar putea arăta astfel:
Defecte- numărul de defecte constatate,
Severitate- criticitatea defectelor constatate,
Complexitate- complexitatea logicii sistemului,
Platformă- platforma de implementare a sistemului,
Fază- faza de proiect,
Perioadă- perioada de timp luată în considerare.
Dar deja un criteriu specific pe care trebuie să-l îndeplinească un tester trebuie să fie selectat empiric și ținând cont de specificul unei anumite organizații.
Nu este încă posibil să luăm în considerare toți factorii în acest moment, cu toate acestea, împreună cu dezvoltatorul nostru principal Ivan Astafiev și managerul de proiect Irina Lager, am ajuns la următoarea formulă, ținând cont de numărul de defecte și de criticitatea acestora:
 , Unde
, Unde
E- eficienta, determinata de numarul de defecte constatate,
D Client- numărul de defecte constatate de client, dar pe care testatorul evaluat a trebuit să le găsească,
D Tester- numărul de defecte constatate de tester,
kși d- factori de corectare pentru numărul total de defecte.
Vreau să remarc imediat că atunci când evaluez folosind această formulă, trebuie luate în considerare numai acele defecte care aparțin domeniului de responsabilitate a testerului evaluat. Dacă mai mulți testeri împărtășesc responsabilitatea pentru un defect ratat, atunci acel defect trebuie luat în considerare atunci când se evaluează fiecare tester. De asemenea, calculul nu ia în considerare defectele critice scăzute.
 Avem astfel o parabolă de gradul al treilea, care reflectă criteriul intensității depistarii defectelor, pe care testerul trebuie să-l respecte. În general, dacă evaluarea unui tester se află deasupra parabolei, aceasta înseamnă că el are performanțe mai bune decât așteptările, dacă este mai scăzută, atunci, în consecință, mai rău.
Avem astfel o parabolă de gradul al treilea, care reflectă criteriul intensității depistarii defectelor, pe care testerul trebuie să-l respecte. În general, dacă evaluarea unui tester se află deasupra parabolei, aceasta înseamnă că el are performanțe mai bune decât așteptările, dacă este mai scăzută, atunci, în consecință, mai rău.
Există aici o nuanță legată de numărul total de defecte analizate. Desigur, cu cât mai multe statistici, cu atât mai bine, dar uneori trebuie să analizezi diferite etape ale proiectului, alteori doar o estimare pentru fiecare perioadă de timp. Un lucru este când s-au constatat 4 defecte în perioada și 2 dintre ele au fost găsite de client, și cu totul altceva când au fost găsite 100 de defecte, iar 50 dintre ele au fost găsite de client. În ambele cazuri, raportul dintre numărul de defecte găsite de client și tester se va dovedi a fi 0,5, dar înțelegem că, în primul caz, nu totul este atât de rău, dar în al doilea, trebuie să sunăm alarma.
Fără prea mult succes, încercând să facem o legătură matematică strictă cu numărul total de defecte, am atașat, după spusele aceleiași Irinei Lager, acestei formule „cârje” sub formă de intervale, pentru fiecare dintre ele am stabilit propriile lor. coeficienți. Au fost trei intervale: pentru statistici de la 1 la 20 de defecte, de la 21 la 60 de defecte și pentru statistici pe mai mult de 60 de defecte.
|
Numărul de defecte |
k |
d |
Fracția admisibilă estimată de defecte constatate de client din numărul total de defecte constatate |
Ultima coloană din tabel a fost introdusă pentru a explica câte defecte poate găsi un client într-un anumit eșantion. În consecință, cu cât eșantionul este mai mic, cu atât eroarea poate fi mai mare și cu atât clientul poate găsi mai multe defecte. Din punct de vedere al funcției, aceasta înseamnă valoarea minimă limită a raportului dintre numărul de defecte constatate de client și tester, după care randamentul devine negativ, sau punctul în care graficul traversează axa X. cu cât eșantionul este mai mic, cu atât ar trebui să fie mai la dreapta intersecția cu axa. În ceea ce privește managementul, aceasta înseamnă că, cu cât eșantionul este mai mic, cu atât o astfel de estimare este mai puțin precisă; prin urmare, pornim de la principiul conform căruia testerii ar trebui să fie evaluați mai puțin riguros pe un eșantion mai mic.
Avem grafice de forma următoare:

Graficul negru reflectă criteriul pentru un eșantion de peste 60 de defecte, galben - pentru 21-60 de defecte, verde - pentru un eșantion cu mai puțin de 20 de defecte. Se poate observa că cu cât eșantionul este mai mare, cu atât graficul traversează mai mult spre stânga axa X. După cum sa menționat deja, pentru evaluator, aceasta înseamnă că cu cât eșantionul este mai mare, cu atât poți avea mai multă încredere în această cifră.
Metoda de evaluare constă în calcularea performanței testerului conform formulei (2), luând în considerare factorii de corecție și compararea acestei estimări cu valoarea cerută din grafic. Dacă scorul este mai mare decât graficul, testerul îndeplinește așteptările, dacă este mai mic, testerul lucrează sub „bara” necesară. De asemenea, vreau să remarc că toate aceste numere au fost selectate empiric, iar pentru fiecare organizație ele pot fi modificate și ajustate mai precis în timp. Prin urmare, orice comentarii (aici sau în blogul meu personal) și îmbunătățiri sunt binevenite.
Această metodă de apreciere a raportului dintre numărul de defecte constatate de echipa de testare și client/utilizator/client mi se pare rezonabilă și mai mult sau mai puțin obiectivă. Este adevărat, o astfel de evaluare poate fi efectuată numai după finalizarea proiectului sau, cel puțin, dacă există utilizatori externi activi ai sistemului. Dar dacă produsul nu este încă folosit? Cum se evaluează munca unui tester în acest caz?
În plus, o astfel de tehnică de evaluare a eficacității unui tester creează câteva probleme suplimentare:
1. Un defect începe să se împartă în câteva mai mici.
· Șeful de testare, care a observat o astfel de situație, ar trebui să o suprime prin metode informale.
2. Gestionarea defectelor devine mai dificilă din cauza numărului tot mai mare de înregistrări duplicat.
· Regulile pentru comiterea defectelor în sistemul de urmărire a erorilor, care includ o revizuire obligatorie pentru defecte similare, pot ajuta la rezolvarea acestei probleme.
3. Lipsa evaluării calității defectelor constatate, întrucât singurul scop al testerului este numărul de defecte și, în consecință, lipsa motivației testerului de a căuta defectele „de calitate”. Cu toate acestea, criticitatea și „calitatea” unui defect nu pot fi echivalate, acesta din urmă fiind un concept mai puțin formalizat.
· Aici „atitudinea” atât a testatorului, cât și a managerului ar trebui să joace un rol decisiv. Numai o înțelegere generală corectă (!) a semnificației unei astfel de evaluări cantitative poate rezolva această problemă.
Rezumând toate cele de mai sus, ajungem la concluzia că nu este doar dificil să evaluezi munca unui tester doar după numărul de defecte constatate, dar nici nu este complet corectă. Prin urmare, numărul de defecte constatate ar trebui să fie doar unul dintre indicatorii evaluării integrale a muncii testatorului, și nu în formă pură, ci ținând cont de factorii pe care i-am enumerat.







