En los últimos años, las pruebas automatizadas se han convertido en una tendencia en el campo del desarrollo de software; en cierto sentido, su implementación se ha convertido en un “homenaje de moda”. Sin embargo, implementar y mantener pruebas automatizadas es un procedimiento que requiere muchos recursos y, por lo tanto, es costoso. El uso generalizado de esta herramienta suele provocar pérdidas financieras importantes sin resultados significativos.
¿Cómo se puede utilizar una herramienta bastante sencilla para evaluar la posible eficacia del uso de pruebas automatizadas en un proyecto?
¿Qué se define como “efectividad” de la automatización de pruebas?
La forma más común de evaluar la eficiencia (principalmente económica) es cálculo del retorno de la inversión(Retorno de la inversión) Se calcula de forma bastante sencilla, siendo la relación entre beneficios y costes. Tan pronto como el valor del ROI supera el uno, la solución devuelve los fondos invertidos y comienza a generar otros nuevos.
En el caso de la automatización, el beneficio significa ahorro en pruebas manuales. Además, las ganancias en este caso pueden no ser obvias; por ejemplo, los resultados de la búsqueda de defectos en el proceso de pruebas ad hoc por parte de ingenieros cuyo tiempo se liberó debido a la automatización. Este beneficio es bastante difícil de calcular, por lo que puedes hacer una suposición (por ejemplo, + 10%) u omitirla.
Sin embargo, el ahorro no siempre es el objetivo de la introducción de la automatización. Un ejemplo es velocidad de prueba(tanto en términos de la velocidad de realización de una prueba como de la frecuencia de las pruebas). Por varias razones, la velocidad de las pruebas puede ser crítica para una empresa, si las inversiones en automatización se recuperan con los beneficios obtenidos.
Otro ejemplo - Eliminando el “factor humano” del proceso de prueba del sistema. Esto es importante cuando la precisión y corrección de las operaciones son críticas para los negocios. El costo de tal error puede ser significativamente mayor que el costo de desarrollar y mantener una prueba automática.
¿Por qué medir el desempeño?
Medir la eficiencia ayuda a responder las preguntas: "¿vale la pena implementar la automatización en un proyecto?", "¿cuándo nos traerá la implementación un resultado significativo?", "¿cuántas horas de pruebas manuales reemplazaremos?", "¿es posible reemplazar?" ¿3 ingenieros de pruebas manuales con 1 ingeniero de pruebas automatizadas? y etc.
Estos cálculos pueden ayudar a formular objetivos (o métricas) para el equipo de pruebas de automatización. Por ejemplo, ahorrar X horas al mes de pruebas manuales y reducir los costos para el equipo de pruebas en Y unidades estándar.
Cada vez que fallamos en otro lanzamiento, comienza el escándalo. Los culpables aparecen inmediatamente y, a menudo, somos nosotros, los evaluadores. Probablemente sea el destino ser el último eslabón en el ciclo de vida del software, por lo que incluso si un desarrollador pasa mucho tiempo escribiendo código, nadie piensa siquiera en el hecho de que las pruebas también son personas que tienen ciertas capacidades.
No puedes saltar por encima de tu cabeza, pero puedes trabajar de 10 a 12 horas. He escuchado frases así muy a menudo)))
Cuando las pruebas no satisfacen las necesidades de la empresa, surge la pregunta: ¿por qué realizar pruebas si no pueden cumplir con los plazos? Nadie piensa en lo que pasó antes, por qué no escribieron los requisitos correctamente, por qué no pensaron en la arquitectura, por qué el código estaba torcido. Pero cuando tienes una fecha límite y no tienes tiempo para completar las pruebas, inmediatamente empiezan a castigarte...
Pero estas fueron algunas palabras sobre la difícil vida de un probador. Ahora al grano :)
Después de un par de estos errores, todo el mundo empieza a preguntarse qué pasa con nuestro proceso de prueba. Quizás usted, como gerente, comprenda los problemas, pero ¿cómo transmitirlos a la gerencia? ¿Pregunta?
La gestión necesita números y estadísticas. Palabras simples: te escucharon, asintieron con la cabeza, dijeron "Adelante, hazlo" y eso es todo. Después de esto, todos esperan un milagro de usted, pero incluso si hizo algo y no funcionó, usted o su gerente nuevamente recibirán un golpe.
Cualquier cambio debe ser respaldado por la gerencia, y para que la gerencia lo respalde, necesitan números, mediciones, estadísticas.
He visto muchas veces cómo intentaron descargar varias estadísticas de los rastreadores de tareas, diciendo que "estamos tomando métricas de JIRA". Pero averigüemos qué es una métrica.
Una métrica es una cantidad medible técnica o procedimentalmente que caracteriza el estado de un objeto de control.
Veamos: nuestro equipo encuentra 50 defectos durante las pruebas de aceptación. ¿Es mucho? ¿O no es suficiente? ¿Estos 50 defectos le informan sobre el estado del objeto de control, en particular, el proceso de prueba?
Probablemente no.
¿Qué pasaría si le dijeran que la cantidad de defectos encontrados durante las pruebas de aceptación es del 80%, aunque debería haber solo el 60%? Creo que queda inmediatamente claro que hay muchos defectos y, en consecuencia, por decirlo suavemente, el código de los desarrolladores es completamente g..... insatisfactorio en términos de calidad.
Alguien podría decir entonces ¿por qué realizar pruebas? Pero diré que los defectos son el tiempo de prueba, y el tiempo de prueba es lo que afecta directamente a nuestro plazo.
Por lo tanto, no solo necesitamos métricas, necesitamos KPI.
KPI es una métrica que sirve como indicador del estado del objeto de control. Un requisito previo es la presencia de un valor objetivo y desviaciones permitidas establecidas.
Es decir, al construir un sistema de métricas, siempre es necesario tener un objetivo y desviaciones aceptables.
Por ejemplo, necesita (su objetivo) que el 90% de todos los defectos se resuelvan en la primera iteración. Al mismo tiempo, entiendes que esto no siempre es posible, pero incluso si el número de defectos resueltos la primera vez es del 70%, eso también es bueno.
Es decir, te has fijado una meta y una desviación aceptable. Ahora bien, si se cuentan los defectos en una versión y se obtiene un valor del 86%, entonces esto ciertamente no es bueno, pero ya no es un fracaso.
Matemáticamente quedaría así:
¿Por qué 2 fórmulas? Esto se debe al hecho de que existe un concepto de métricas ascendentes y descendentes, es decir, cuando nuestro valor objetivo se acerca al 100% o al 0%.
Aquellos. Si hablamos, por ejemplo, de la cantidad de defectos encontrados después de la implementación en funcionamiento industrial, cuanto menos, mejor, pero si hablamos de cubrir la funcionalidad con casos de prueba, entonces todo será al revés.
Al mismo tiempo, no te olvides de cómo calcular tal o cual métrica.
Para obtener los porcentajes, piezas, etc. que necesitamos, debemos calcular cada métrica.
Para ver un ejemplo claro, les hablaré de la métrica "Oportunidad del procesamiento de defectos mediante pruebas".
Utilizando un enfoque similar al que describí anteriormente, también formulamos un KPI para la métrica basado en los valores objetivo y las desviaciones.
¡No te asustes, en la vida real no es tan difícil como parece en la imagen!

¿Que tenemos?
Bueno, está claro que el número de liberación, el número de incidente….
Crítico - coeficiente. 5,
Mayor: probabilidades. 3,
Menor - coeficiente. 1.5.
A continuación, debe especificar el SLA para el tiempo de procesamiento del defecto. Para hacer esto, se determinan el valor objetivo y el tiempo máximo permitido de repetición de prueba, de manera similar a como lo describí anteriormente para calcular métricas.
Para responder estas preguntas, pasaremos directamente al indicador de desempeño y haremos la pregunta de inmediato. Cómo calcular el indicador si el valor de una solicitud puede ser "cero". Si uno o más indicadores son iguales a cero, entonces el indicador final disminuirá mucho, por lo que surge la pregunta de cómo equilibrar nuestro cálculo para que los valores cero, por ejemplo, de consultas con un coeficiente de gravedad de "1" no sean muy diferentes. afectar nuestra evaluación final.
Peso- este es el valor que necesitamos para tener el menor impacto en la evaluación final de las solicitudes con un coeficiente de severidad bajo, y viceversa, una solicitud con el coeficiente de severidad más alto tiene un impacto grave en la evaluación, siempre que tengamos superado el plazo para esta solicitud.
Para asegurarnos de que no tenga ningún malentendido en los cálculos, introduciremos variables específicas para el cálculo:
x es el tiempo real dedicado a volver a probar el defecto;
y - desviación máxima permitida;
z - coeficiente de gravedad.
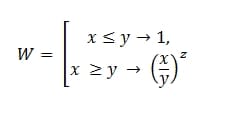
O en lenguaje común, esto es:
W=ESLI(X<=y,1,(x/y)^z)
Por lo tanto, incluso si superamos nuestros límites de SLA, nuestra solicitud, dependiendo de la gravedad, no afectará seriamente nuestros resultados.
Todo es como se describe arriba:
X– tiempo real dedicado a la nueva prueba de defectos;
y– desviación máxima permitida;
z– coeficiente de gravedad.
h – tiempo planificado según SLA
Ya no sé cómo expresar esto en una fórmula matemática, así que lo escribiré en lenguaje de programa con el operador SI.
R = SI(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
Como resultado, obtenemos que si hemos logrado el objetivo, entonces nuestro valor solicitado es igual a 1, si hemos ido más allá de la desviación permitida, entonces la calificación es igual a cero y se calculan los pesos.
Si nuestro valor está entre el objetivo y la desviación máxima permitida, entonces dependiendo del coeficiente de gravedad, nuestro valor varía en el rango.
Ahora daré un par de ejemplos de cómo se verá esto en nuestro sistema de métricas.
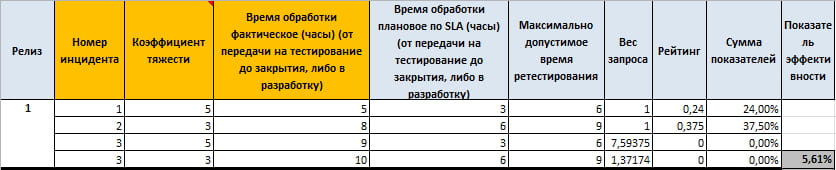
Cada solicitud, dependiendo de su importancia (factor de gravedad), tiene su propio SLA.
¿Qué vemos aquí?
En la primera solicitud nos desviamos solo una hora de nuestro valor objetivo y ya tenemos una calificación del 30%, mientras que en la segunda solicitud también nos desviamos solo una hora, pero la suma de los indicadores ya no es del 30%, sino 42,86%. Es decir, los coeficientes de gravedad juegan un papel importante en la formación de la puntuación final de la consulta.
Al mismo tiempo, en la tercera solicitud violamos el tiempo máximo permitido y la calificación es igual a cero, pero el peso de la solicitud ha cambiado, lo que nos permite calcular más correctamente el impacto de esta solicitud en el coeficiente final.
Bueno, para comprobarlo, basta con calcular que la media aritmética de los indicadores será igual a 43,21%, y obtuvimos 33,49%, lo que indica la grave influencia de las consultas de gran importancia.
Cambiemos los valores en el sistema a 1 hora.
al mismo tiempo, para la quinta prioridad el valor cambió un 6% y para la tercera un 5,36%.
Nuevamente, la importancia de la solicitud afecta su puntuación.

Eso es todo, obtenemos la métrica final.
¡Lo que es importante!
No estoy diciendo que el uso de un sistema de métricas deba hacerse por analogía con mis valores, solo estoy sugiriendo un enfoque para mantenerlos y recopilarlos.
En una organización vi que habían desarrollado su propio marco para recopilar métricas de HP ALM y JIRA. Esto es realmente genial. Pero es importante recordar que dicho proceso de mantenimiento de métricas requiere un estricto cumplimiento de los procesos regulatorios.
Bueno, lo más importante es que sólo tú puedes decidir cómo y qué métricas recopilar. No es necesario copiar métricas que no puedas recopilar.
El enfoque es complejo, pero eficaz.
¡Pruébalo y quizás tú también lo logres!
Alexander Meshkov, director de operaciones de Performance Lab, tiene más de cinco años de experiencia en pruebas de software, gestión de pruebas y consultoría de control de calidad. Experto ISTQB, TPI, TMMI.
El objetivo de la evaluación del rendimiento, que algunos ya han llamado la “fórmula de la desgracia”, es precisamente hacer feliz al evaluador, para que pueda demostrar con números que uno trabaja bien y que por ello hay que felicitarlo, y el otro es malo y debe ser azotado... La evaluación solo según este criterio no puede ser la única, por lo que debe considerarse en conjunto con otros indicadores, como implementación del plan, automatización de pruebas, etc.
El desempeño de un evaluador, como el de cualquier otro empleado, debe evaluarse cuantitativamente, es decir, en indicadores mensurables. Pero, ¿qué indicadores debería elegir?
Lo primero que me viene a la mente es la cantidad de defectos encontrados. Y fue precisamente este indicador el que inmediatamente intenté introducir en Inreco LAN. Sin embargo, inmediatamente surgió una acalorada discusión que me impulsó a analizar este criterio. Quiero discutir este tema en este artículo.
El número de defectos encontrados es un indicador extremadamente resbaladizo. Todos los recursos en la red que discuten este problema dicen lo mismo (http://www.software-testing.ru/, blogs.msdn.com/imtesty, it4business.ru, sqadotby.blogspot.com, blogs.msdn. com /larryosterman, sql.ru, http://www.testingperspective.com/ y muchos, muchos otros). Después de analizar mi propia experiencia y estos recursos, llegué al siguiente árbol de problemas:
En primer lugar, defecto a defecto es discordia. Un evaluador puede buscar defectos en la disposición de los botones de la aplicación, otro puede profundizar en la lógica y proponer situaciones de prueba complejas. En la mayoría de los casos, el primer evaluador encontrará más defectos, porque le llevará mucho menos tiempo incluso preparar la prueba, pero el valor de dichos defectos es mucho menor. Este problema se resuelve fácilmente introduciendo la criticidad de los defectos. Puede evaluar la cantidad de defectos encontrados en cada categoría. Por ejemplo, tenemos 4 de ellos: crítico, significativo, medio e insignificante. Pero dado que los límites de la definición de criticidad no están del todo claros, aunque tenemos signos formales de criticidad, podemos seguir dos caminos más confiables. La primera es que una cierta parte de los defectos encontrados durante el período asignado no deben ser defectos poco críticos. La segunda es no tener en cuenta defectos menores a la hora de valorar. Por lo tanto, luchamos contra el deseo del evaluador de recolectar tantos defectos como sea posible describiendo fallas menores, obligándolo (o más a menudo a ella) a profundizar más y encontrar defectos graves. Y siempre existen, cree en mi experiencia. Elegí la segunda opción: descartar defectos menores.
La segunda razón del "resbaladizo" de tal criterio es la presencia de un número suficiente de defectos en el sistema para que el evaluador los encuentre. Hay tres factores aquí. La primera es la complejidad de la lógica y la tecnología del sistema. El segundo es la calidad de la codificación. Y la tercera es la etapa del proyecto. Veamos estos tres factores en orden. La complejidad de la lógica y la tecnología en la que está escrito el sistema afecta los posibles fallos que se puedan cometer. Además, la dependencia aquí dista mucho de ser directa. Si implementa una lógica simple en una plataforma compleja o desconocida, los errores se asociarán principalmente con el uso incorrecto de la tecnología de implementación. Si implementa una lógica compleja en una plataforma primitiva, lo más probable es que los errores estén asociados tanto con la lógica misma como con la complejidad de implementar dicha lógica en un lenguaje primitivo. Es decir, se necesita un equilibrio a la hora de elegir la tecnología de implementación del sistema. Pero a menudo la tecnología la dicta el cliente o el mercado, por lo que es poco probable que podamos influir en ella. Esto significa que solo queda tener en cuenta este factor como un cierto coeficiente del número potencial de defectos. Además, lo más probable es que el valor de este coeficiente deba ser determinado por un experto.
Calidad de codificación. Aquí definitivamente no podemos influir en el desarrollador de ninguna manera. Pero podemos: a) evaluar nuevamente de manera experta el nivel del desarrollador e incluirlo como un factor más y b) intentar prevenir errores en el código mediante pruebas unitarias, haciendo que la cobertura del código del 100% mediante pruebas unitarias sea un requisito obligatorio.
Etapa del proyecto. Se sabe desde hace mucho tiempo que es imposible encontrar todos los defectos, excepto en un programa trivial o por accidente, ya que no hay límite para la perfección y cualquier discrepancia con la perfección puede considerarse un defecto. Pero una cosa es cuando un proyecto está en fase de desarrollo activo y otra cuando está en fase de soporte. Y si también tenemos en cuenta la complejidad del sistema, la tecnología y la calidad de la codificación, entonces está claro que todo esto afecta radicalmente la cantidad de defectos que el evaluador es capaz de encontrar. A medida que el proyecto se acerca a su finalización o a la fase de soporte (lo llamamos todo condicionalmente y ahora lo definimos intuitivamente), la cantidad de defectos en el sistema disminuye y, por lo tanto, la cantidad de defectos encontrados también disminuye. Y aquí es necesario determinar el momento en que ya no es razonable exigir que el probador encuentre una cierta cantidad de defectos. Para determinar ese momento, sería bueno saber qué parte del número total de defectos podemos encontrar y cuántos defectos quedan todavía en el sistema. Este es un tema para una discusión separada, pero se puede aplicar un método estadístico bastante simple y efectivo.
A partir de las estadísticas de proyectos anteriores, es posible comprender, con cierto error, cuántos defectos había en el sistema y cuántos fueron encontrados por el equipo de pruebas durante los diferentes períodos del proyecto. Por tanto, es posible obtener un cierto indicador medio de la eficacia del equipo de pruebas. Se puede descomponer para cada evaluador individual y obtener una evaluación personal. Cuanta más experiencia y estadísticas, menor será el error. También podemos utilizar el método de “siembra de errores”, cuando sabemos exactamente cuántos errores hay en el sistema. Naturalmente, es necesario tener en cuenta factores adicionales, como el tipo de sistema, la complejidad lógica, la plataforma, etc. Así, obtenemos una relación entre la fase del proyecto y el porcentaje de defectos encontrados. Ahora podemos aplicar esta relación en sentido contrario: conociendo el número de defectos encontrados y la fase actual del proyecto, podemos determinar el número total de defectos de nuestro sistema (con algún error, claro). Y luego, basándose en indicadores de evaluación personales o generales, puede determinar cuántos defectos puede encontrar un evaluador o equipo en el período de tiempo restante. A partir de esta evaluación, ya es posible determinar el criterio para la efectividad del trabajo del evaluador.
La función del indicador de rendimiento del probador podría verse así:
Defectos– número de defectos encontrados,
Gravedad– criticidad de los defectos encontrados,
Complejidad– complejidad de la lógica del sistema,
Plataforma– plataforma de implementación del sistema,
Fase- fase del proyecto,
Período– el período de tiempo considerado.
Pero el criterio específico que debe cumplir un evaluador debe seleccionarse empíricamente y teniendo en cuenta las características específicas de una organización en particular.
Por el momento, todavía no es posible tener en cuenta todos los factores, sin embargo, junto con nuestro desarrollador principal Ivan Astafiev y la directora de proyecto Irina Lager, llegamos a la siguiente fórmula que tiene en cuenta el número de defectos y su criticidad:
 , Dónde
, Dónde
mi– eficiencia, determinada por el número de defectos encontrados,
D Cliente– el número de defectos encontrados por el cliente, pero que el evaluador debería haber encontrado,
Probador D– el número de defectos encontrados por el probador,
k Y d– factores de corrección para el número total de defectos.
Me gustaría señalar de inmediato que al evaluar el uso de esta fórmula, es necesario tener en cuenta solo aquellos defectos que caen dentro del área de responsabilidad del evaluador evaluado. Si varios evaluadores comparten la responsabilidad por un defecto omitido, entonces ese defecto debe tenerse en cuenta al evaluar a cada evaluador. Además, el cálculo no tiene en cuenta los defectos poco críticos.
 Por lo tanto, tenemos una parábola de tercer grado, que refleja el criterio de intensidad de detección de defectos que debe cumplir el evaluador. En general, si la puntuación del evaluador está por encima de la parábola, esto significa que trabaja mejor de lo esperado; si es menor, entonces, en consecuencia, peor.
Por lo tanto, tenemos una parábola de tercer grado, que refleja el criterio de intensidad de detección de defectos que debe cumplir el evaluador. En general, si la puntuación del evaluador está por encima de la parábola, esto significa que trabaja mejor de lo esperado; si es menor, entonces, en consecuencia, peor.
Aquí hay un matiz relacionado con el número total de defectos analizados. Naturalmente, cuantas más estadísticas, mejor, pero a veces es necesario analizar diferentes etapas del proyecto, a veces solo necesitas una evaluación para cada período de tiempo. Y una cosa es que en un periodo se encuentren 4 defectos y 2 de ellos sean obra del cliente, y otra muy distinta cuando se encuentren 100 defectos y 50 de ellos sean obra del cliente. En ambos casos, la relación entre el número de defectos encontrados por el cliente y el probador será igual a 0,5, pero entendemos que en el primer caso no todo es tan malo, y en el segundo es hora de hacer sonar la alarma.
Habiendo intentado, sin mucho éxito, establecer una conexión matemática estricta con el número total de defectos, adjuntamos, en palabras de la misma Irina Lager, a esta fórmula "muletas" en forma de intervalos, para cada uno de los cuales determinamos el nuestro. coeficientes. Había tres intervalos: para estadísticas de 1 a 20 defectos, de 21 a 60 defectos y para estadísticas de más de 60 defectos.
|
Número de defectos |
k |
d |
Porción aceptable estimada de defectos encontrados por el cliente sobre el número total de defectos encontrados |
La última columna de la tabla se incluye para explicar cuántos defectos puede encontrar el cliente en una muestra determinada. En consecuencia, cuanto más pequeña sea la muestra, mayor será el error y más defectos podrá encontrar el cliente. Desde el punto de vista de la función, esto significa el valor mínimo máximo de la relación entre el número de defectos encontrados por el cliente y el probador, después del cual la eficiencia se vuelve negativa, o el punto en el que el gráfico cruza el eje X. Eso es cuanto más pequeña sea la muestra, más a la derecha debe estar la intersección con el eje. En términos de gestión, esto significa que cuanto más pequeña es la muestra, menos precisa es dicha evaluación, por lo que partimos del principio de que en una muestra más pequeña es necesario evaluar a los evaluadores de manera menos estricta.
Tenemos los siguientes gráficos:

El gráfico negro refleja el criterio para una muestra de más de 60 defectos, el amarillo, para entre 21 y 60 defectos, el verde, para una muestra de menos de 20 defectos. Se puede ver que cuanto mayor es la muestra, más hacia la izquierda el gráfico se cruza con el eje X. Como ya se mencionó, para el empleado evaluador esto significa que cuanto mayor sea la muestra, más podrá confiar en esta cifra.
El método de evaluación consiste en calcular el desempeño del probador utilizando la fórmula (2) teniendo en cuenta los factores de corrección y comparando esta evaluación con el valor requerido en el gráfico. Si la puntuación está por encima del cronograma, el evaluador cumple con las expectativas; si es inferior, el evaluador está trabajando por debajo de la “barra” requerida. También me gustaría señalar que todas estas cifras se seleccionaron empíricamente y para cada organización se pueden cambiar y seleccionar con mayor precisión a lo largo del tiempo. Por tanto, agradezco cualquier comentario (aquí o en mi blog personal) y mejoras.
Este método de evaluación basado en la relación entre el número de defectos encontrados por el equipo de pruebas y el cliente/usuario/cliente me parece razonable y más o menos objetivo. Es cierto que dicha evaluación sólo puede llevarse a cabo después de la finalización del proyecto o, como mínimo, si hay usuarios externos activos del sistema. ¿Pero qué pasa si el producto aún no se utiliza? ¿Cómo evaluar el trabajo del evaluador en este caso?
Además, este método de evaluar la eficacia de un probador plantea varios problemas adicionales:
1. Un defecto comienza a dividirse en varios más pequeños.
· El responsable de pruebas que advierta tal situación debe detenerla utilizando métodos informales.
2. La gestión de defectos se vuelve más compleja debido al creciente número de registros duplicados.
· Las reglas para notificar defectos en el sistema de seguimiento de errores, incluida la revisión obligatoria de la presencia de defectos similares, pueden ayudar a resolver este problema.
3. Falta de evaluación de la calidad de los defectos encontrados, ya que el único objetivo del evaluador es el número de defectos y, como resultado, el evaluador carece de motivación para buscar defectos de “calidad”. Aun así, no se puede equiparar la criticidad y la “calidad” de un defecto; el segundo es un concepto menos formalizado.
· Aquí el papel decisivo debe jugarlo el “estado de ánimo” tanto del evaluador como del director. Sólo una comprensión general correcta (!) del significado de tal evaluación cuantitativa puede resolver este problema.
Resumiendo todo lo anterior, llegamos a la conclusión de que evaluar el trabajo de un probador solo por la cantidad de defectos encontrados no solo es difícil, sino que tampoco es del todo correcto. Por lo tanto, el número de defectos encontrados debe ser sólo uno de los indicadores de una evaluación integral del trabajo del evaluador, y no en su forma pura, sino teniendo en cuenta los factores que he enumerado.







