Under de senaste åren har automatiserad testning blivit en trend inom mjukvaruutveckling, på sätt och vis har dess implementering blivit en "feed to fashion". Implementeringen och stödet av automatiserade tester är dock en mycket resurskrävande och följaktligen dyr procedur. Den utbredda användningen av detta verktyg leder oftast till betydande ekonomiska förluster utan något betydande resultat.
Hur kan du använda ett ganska enkelt verktyg för att utvärdera den möjliga effektiviteten av att använda autotester på ett projekt?
Vad definieras som "effektivitet" av testautomatisering?
Det vanligaste sättet att utvärdera effektivitet (främst ekonomiskt) är avkastningsberäkning(ROI). Det är helt enkelt beräknat, vilket är förhållandet mellan vinst och kostnader. Så snart ROI-värdet överstiger ett, ger lösningen tillbaka pengarna som investerats i den och börjar ge nya.
Vid automatisering betyder vinst besparingar på manuell testning. Dessutom kan vinsten i det här fallet inte vara uppenbar - till exempel resultaten av att hitta defekter i processen för ad-hoc-testning av ingenjörer, vars tid frigjordes på grund av automatisering. En sådan vinst är ganska svår att beräkna, så du kan antingen göra ett antagande (till exempel + 10%) eller utelämna det.
Men att spara är inte alltid målet med att implementera automatisering. Ett exempel är testkörningshastighet(både när det gäller hastigheten för att utföra ett test, och när det gäller testfrekvensen). Av flera skäl kan testhastigheten vara avgörande för ett företag – om investeringar i automation lönar sig med den mottagna vinsten.
Ett annat exempel - uteslutning av den "mänskliga faktorn" från systemtestningsprocessen. Detta är viktigt när noggrannheten och korrektheten i utförandet av verksamheten är avgörande för verksamheten. Priset för ett sådant fel kan vara mycket högre än kostnaden för att utveckla och underhålla ett autotest.
Varför mäta prestanda?
Effektivitetsmätning hjälper till att svara på frågorna: "Är det värt att implementera automatisering i ett projekt?", "När kommer implementeringen att ge oss ett betydande resultat?", "Hur många timmars manuell testning kommer vi att ersätta?", "Är det möjligt att ersätta 3 manuella testingenjörer med 1 automatiserad testingenjör ? och så vidare.
Dessa beräkningar kan hjälpa till att formulera mål (eller mätvärden) för det automatiserade testteamet. Till exempel att spara X timmar per månad av manuell testning, vilket minskar kostnaden för testteamet med Y-enheter.
Varje gång vi misslyckas med en annan release är det tjafs. Det dyker genast upp skyldiga människor, och ofta är det vi som testar. Det är förmodligen ödet att vara den sista länken i mjukvarans livscykel, så även om en utvecklare lägger ner mycket tid på att skriva kod är det ingen som ens tror att testning också är personer med vissa förmågor.
Du kan inte hoppa över huvudet, men du kan arbeta 10-12 timmar om dagen. Jag hörde sådana fraser väldigt ofta)))
När testning inte uppfyller verksamhetens behov, då uppstår frågan, varför testa överhuvudtaget om de inte hinner jobba i tid. Ingen tänker på vad som hände innan, varför kraven inte skrevs ordentligt, varför arkitekturen inte var genomtänkt, varför koden var sned. Men när du har en deadline och du inte har tid att slutföra testning, börjar de omedelbart straffa dig ...
Men det var några ord om det svåra livet som en testare. Nu till saken 🙂
Efter ett par sådana förfalskningar börjar alla undra vad som är fel i vår testprocess. Kanske förstår du som ledare problemen, men hur förmedlar du dem till ledningen? Fråga?
Ledningen behöver siffror, statistik. Enkla ord - de lyssnade på dig, nickade med huvudet, sa - "Kom igen, gör det" och det är allt. Efter det förväntar sig alla ett mirakel av dig, men även om du gjorde något och det inte fungerade för dig, får du eller din ledare en hatt igen.
Varje förändring måste stödjas av ledningen och för att ledningen ska kunna stödja den behöver de siffror, mätningar, statistik.
Många gånger såg jag hur de försökte ladda upp olika statistik från uppgiftsspårare och sa att "Vi tar bort mätvärden från JIRA". Men låt oss förstå vad ett mått är.
Ett mått är ett tekniskt eller procedurmässigt mätbart värde som kännetecknar kontrollobjektets tillstånd.
Låt oss se - vårt team hittar 50 defekter under acceptanstestning. Det är mycket? Eller lite? Berättar dessa 50 defekter dig om tillståndet för kontrollobjektet, i synnerhet testprocessen?
Antagligen inte.
Och om du fick veta att antalet defekter som hittats under acceptanstestning är 80 %, medan det bara borde vara 60 %. Jag tror att det är omedelbart klart att det finns många defekter, respektive, milt sagt, utvecklarens kod är helt g ... .. otillfredsställande vad gäller kvalitet.
Någon kan säga att varför då testa? Men jag kommer att säga att defekter är testtid, och testtid är det som direkt påverkar vår deadline.
Därför behöver vi inte bara mätvärden, vi behöver nyckeltal.
KPI är ett mått som fungerar som en indikator på kontrollobjektets tillstånd. En förutsättning är närvaron av ett målvärde och fastställda toleranser.
Det vill säga alltid, när man bygger ett system med mått måste man ha ett mål och tillåtna avvikelser.
Till exempel behöver du (ditt mål) att 90 % av alla defekter är lösta från första iterationen. Samtidigt förstår du att detta inte alltid är möjligt, men även om antalet defekter som åtgärdas första gången är 70% så är detta också bra.
Det vill säga att du sätter dig ett mål och en acceptabel avvikelse. Nu, om du räknar defekterna i releasen och får ett värde på 86%, så är detta verkligen inte bra, men det är inte längre ett misslyckande.
Matematiskt ser det ut så här:
Varför 2 formler? Detta beror på att det finns ett koncept med stigande och fallande mått, d.v.s. när vårt målvärde närmar sig 100 % eller 0 %.
De där. om vi till exempel talar om antalet defekter som hittats efter implementering i kommersiell drift, ju färre desto bättre, och om vi talar om att täcka funktionaliteten med testfall, så blir allt tvärtom.
Samtidigt, glöm inte hur man beräknar det här eller det måttet.
För att få de procentsatser, bitar, etc. vi behöver, måste vi beräkna varje måttenhet.
Som ett illustrativt exempel kommer jag att berätta om måttet "Lidlighet för defektbearbetning genom testning".
Med ett liknande tillvägagångssätt, som jag beskrev ovan, bildar vi också en KPI för måttet baserat på målvärdena och avvikelser.
Oroa dig inte, det är inte så svårt i verkligheten som det ser ut på bilden!

Det vi har?
Jo, det är klart att releasenumret, incidentnumret ....
Kritisk - odds. fem,
Major - odds. 3,
Mindre - odds. 1.5.
Därefter måste du ange SLA för defektens handläggningstid. För att göra detta bestäms målvärdet och den maximala tillåtna omtesttiden, liknande hur jag beskrev det ovan för beräkning av mätvärden.
För att besvara dessa frågor går vi direkt till resultatmåttet och ställer frågan direkt. Och hur man beräknar indikatorn om värdet på en begäran kan vara lika med "noll". Om en eller flera indikatorer är lika med noll, kommer den slutliga indikatorn att minska väldigt mycket, så frågan uppstår hur vi ska balansera vår beräkning så att nollvärden, till exempel för förfrågningar med en allvarlighetsfaktor på "1", inte gör så mycket påverka vår slutliga bedömning.
Viktär det värde vi behöver för att ha minsta möjliga inverkan av förfrågningar på slutresultatet med låg svårighetsgrad, och vice versa, en förfrågan med högst svårighetsgrad har en allvarlig inverkan på poängen, förutsatt att vi är försenade med denna begäran.
För att du inte ska ha missförstånd i beräkningarna kommer vi att införa specifika variabler för beräkningen:
x är den faktiska tid som går åt till att testa om defekten;
y är den maximala tillåtna avvikelsen;
z är gravitationsfaktorn.
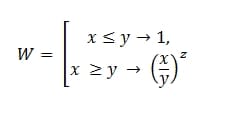
Eller på vanligt språk är detta:
W=ESLI(x<=y,1,(x/y)^z)
Så även om vi gick utöver de SLA-gränser vi satt, kommer vår begäran, beroende på svårighetsgraden, inte att allvarligt påverka vårt slutresultat.
Allt enligt beskrivningen ovan:
X– faktisk tid som ägnat åt att omtesta defekten;
y– Den högsta tillåtna avvikelsen.
zär gravitationsfaktorn.
h- planerad tid enligt SLA
Jag vet inte längre hur man uttrycker detta i en matematisk formel, så jag kommer att skriva på ett programmeringsspråk med operatören OM.
R = OM(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
Som ett resultat får vi att om vi nådde målet så är vårt förfrågningsvärde lika med 1, om vi gick bortom den tillåtna avvikelsen är betyget lika med noll och vikterna beräknas.
Om vårt värde ligger mellan målet och den maximalt tillåtna avvikelsen, varierar vårt värde i intervallet beroende på allvarlighetsfaktorn.
Nu ska jag ge ett par exempel på hur det kommer att se ut i vårt mätsystem.
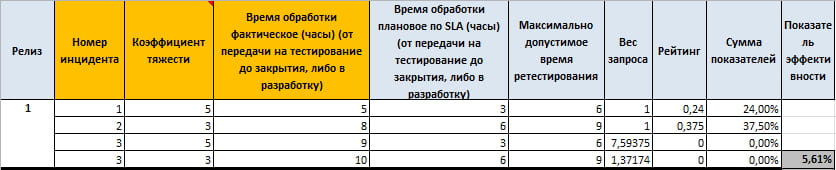
Varje begäran har sin egen SLA beroende på deras betydelse (allvarlighetsfaktor).
Vad ser vi här.
I den första begäran avvek vi bara från vårt målvärde med en timme och har redan en rating på 30 %, medan vi i den andra begäran också avvek med bara en timme, men summan av indikatorerna är inte längre 30 %, men 42,86 %. Det vill säga att svårighetskoefficienterna spelar en viktig roll i bildandet av den slutliga indikatorn för begäran.
Samtidigt, i den tredje begäran, brutit vi mot den maximalt tillåtna tiden och betyget är lika med noll, men vikten av begäran har ändrats, vilket gör att vi kan mer korrekt beräkna effekten av denna begäran på den slutliga koefficienten.
Tja, för att vara säker på detta kan du helt enkelt beräkna att det aritmetiska medelvärdet av indikatorerna kommer att vara 43,21%, och vi fick 33,49%, vilket indikerar en allvarlig påverkan av förfrågningar med hög betydelse.
Låt oss ändra värdena i systemet till 1 timme.
samtidigt, för den 5:e prioriteten, ändrades värdet med 6% och för den tredje - med 5,36%.
Återigen, vikten av en fråga påverkar dess poäng.

Det är det, vi får den slutliga indikatorn på måttet.
Vad är viktigt!
Jag säger inte att användningen av metriksystemet ska göras i analogi med mina värderingar, jag föreslår bara ett tillvägagångssätt för att underhålla och samla in dem.
I en organisation såg jag att de utvecklat sitt eget ramverk för att samla in mätvärden från HP ALM och JIRA. Det är riktigt coolt. Men det är viktigt att komma ihåg att en sådan process för att upprätthålla mått kräver allvarlig efterlevnad av regulatoriska processer.
Tja, och viktigast av allt, bara du kan bestämma hur och vilka mätvärden du samlar in. Du behöver inte kopiera de mätvärden som du inte kan samla in.
Tillvägagångssättet är komplext men effektivt.
Prova och kanske du också kan!
Alexander Meshkov, Chief Operations Officer på Performance Lab, har över 5 års erfarenhet av mjukvarutestning, testhantering och QA-rådgivning. Expert ISTQB, TPI, TMMI.
Målet med prestationsutvärdering, som vissa redan har kallat "olycksformeln" är bara att göra testaren glad, så att du med siffror kan visa att en fungerar bra, och att du måste klappa honom på huvudet för det, och annat är dåligt - och du måste piska honom ... Utvärdering endast enligt detta kriterium kan inte vara den enda, därför bör den övervägas i samband med andra indikatorer, såsom genomförandet av planen, testautomatisering etc.
En testares prestation, liksom alla andra anställda, bör kvantifieras, d.v.s. i en mätbar indikator. Men vilka indikatorer ska man välja?
Det första som kommer att tänka på är antalet upptäckta defekter. Och det var denna indikator som jag omedelbart försökte införa i Inreco LAN. En het diskussion uppstod dock omedelbart, vilket fick mig att analysera detta kriterium. Om detta ämne vill jag diskutera i den här artikeln.
Antalet upptäckta defekter är en extremt hala indikator. Alla resurser på nätverket som diskuterar detta problem upprepar också detta (http://www.software-testing.ru/, blogs.msdn.com/imtesty, it4business.ru, sqadotby.blogspot.com, blogs.msdn.com / larryosterman , sql.ru , http://www.testingperspective.com/ och många, många andra). Efter att ha analyserat min egen erfarenhet och dessa resurser kom jag till följande problemträd:
Först defekt till defekt - disharmoni. En testare kan leta efter defekter i placeringen av knappar i applikationen, den andra kan fördjupa sig i logiken och komma på komplexa testsituationer. I de flesta fall kommer den första testaren att hitta fler defekter, eftersom även förberedelsen av testet kommer att ta honom mycket mindre tid, men värdet av sådana defekter är mycket lägre. Detta problem löses enkelt genom att introducera defektens kriticitet. Det kan utvärderas utifrån antalet defekter som finns i var och en av kategorierna. Till exempel har vi fyra av dem: kritiska, betydande, medelstora och obetydliga. Men eftersom gränsen för att definiera kritikalitet inte är helt klar, även om vi har formella tecken på kritikalitet, kan vi gå två mer tillförlitliga vägar. Den första är att en viss del av de defekter som upptäcks under den valda perioden bör vara icke-kritiska defekter. Det andra är att inte ta hänsyn till mindre brister i bedömningen. På så sätt kämpar vi mot testarens önskan att samla in så många defekter som möjligt genom att beskriva mindre brister, vilket tvingar honom (eller oftare henne) att gräva djupare och hitta allvarliga defekter. Och det är de alltid, tro min erfarenhet. Jag valde det andra alternativet - kassera mindre defekter.
Det andra skälet till "halheten" av ett sådant kriterium är närvaron av ett tillräckligt antal defekter i systemet så att testaren kan hitta dem. Det finns tre faktorer här. Den första är komplexiteten i systemets logik och teknik. Det andra är kvaliteten på kodningen. Och den tredje är projektstadiet. Låt oss ta dessa tre faktorer i ordning. Komplexiteten i logiken och tekniken som systemet är skrivet på påverkar de potentiella brister som kan göras. Dessutom är beroendet här långt ifrån direkt. Om du implementerar enkel logik på en komplex eller obekant plattform, kommer felen huvudsakligen att vara relaterade till felaktig användning av implementeringstekniken. Om du implementerar komplex logik på en primitiv plattform, kommer fel troligen att vara associerade både med själva logiken och med komplexiteten i att implementera sådan logik på ett primitivt språk. Det vill säga att det behövs en balans när man väljer teknik för att implementera systemet. Men ofta är tekniken dikterad av kunden eller marknaden, så vi kan knappast påverka. Därför återstår det bara att ta hänsyn till denna faktor som en viss koefficient för det potentiella antalet defekter. Dessutom måste värdet av denna koefficient troligen bestämmas av en expert.
Kodningskvalitet. Här kan vi definitivt inte påverka utvecklaren på något sätt. Men vi kan: a) igen, sakkunnigt utvärdera utvecklarens nivå och inkludera den som en annan faktor, och b) försöka förhindra uppkomsten av fel i koden genom enhetstester, vilket gör 100 % kodtäckning med enhetstester till ett obligatoriskt krav .
Projektstadiet. Det har länge varit känt att det är omöjligt att hitta alla defekter, utom kanske för ett trivialt program eller av en slump, eftersom det inte finns någon gräns för perfektion, och varje diskrepans med perfektion kan betraktas som en defekt. Men det är en sak när ett projekt är i det aktiva utvecklingsstadiet och en helt annan när det är i stödfasen. Och om vi också tar hänsyn till faktorerna systemkomplexitet och teknik och kodningskvalitet, är det tydligt att allt detta radikalt påverkar antalet defekter som en testare kan hitta. När projektet närmar sig slutförandet eller supportfasen (vi kallar det hela villkorligt och definierar det intuitivt nu), minskar antalet defekter i systemet, och därmed antalet upptäckta defekter också. Och här är det nödvändigt att bestämma det ögonblick då det blir orimligt att kräva att testaren ska hitta ett visst antal defekter. För att fastställa ett sådant ögonblick skulle det vara trevligt att veta vilken del av det totala antalet defekter vi kan hitta och hur många defekter som fortfarande finns kvar i systemet. Detta är ett ämne för en separat diskussion, men en ganska enkel och effektiv statistisk metod kan tillämpas.
Baserat på statistik från tidigare projekt är det möjligt att, med ett visst fel, förstå hur många defekter som fanns i systemet och hur många som upptäcktes av testteamet under olika perioder av projektet. Således kan du få en viss genomsnittlig indikator på testteamets effektivitet. Den kan brytas ner för varje enskild testare och få en personlig bedömning. Ju mer erfarenhet och statistik, desto mindre blir felet. Du kan också använda metoden "error seeding", när vi vet exakt hur många fel som finns i systemet. Naturligtvis måste ytterligare faktorer beaktas, såsom typen av system, logikens komplexitet, plattformen och så vidare. Så vi får förhållandet mellan projektets fas och andelen upptäckta defekter. Nu kan vi tillämpa detta beroende i motsatt riktning: genom att känna till antalet defekter som hittats och den aktuella fasen av projektet, kan vi bestämma det totala antalet defekter i vårt system (med visst fel, naturligtvis). Och sedan, baserat på indikatorerna för en personlig eller övergripande bedömning, kan du bestämma hur många defekter en testare eller ett team kan hitta under den återstående tiden. Baserat på denna bedömning är det redan möjligt att bestämma kriteriet för testarens effektivitet.
Testarens prestandaindikatorfunktion kan se ut så här:
Defekter- antalet upptäckta defekter,
Allvarlighetsgrad– kritikaliteten hos upptäckta defekter,
Komplexitet– komplexiteten i systemlogiken,
plattform– Systemimplementeringsplattform,
Fas- projektets fas,
periodär den aktuella tidsperioden.
Men redan ett specifikt kriterium som en testare måste uppfylla måste väljas empiriskt och med hänsyn till specifikationerna för en viss organisation.
Det är ännu inte möjligt att ta hänsyn till alla faktorer för tillfället, men tillsammans med vår huvudutvecklare Ivan Astafiev och projektledaren Irina Lager kom vi fram till följande formel som tar hänsyn till antalet defekter och deras kritikalitet:
 , var
, var
E– effektivitet, bestäms av antalet upptäckta defekter,
D Kund– antalet defekter som hittats av kunden, men som den bedömda testaren borde ha hittat,
D Testare- antalet defekter som hittats av testaren,
k Och d– Korrigeringsfaktorer för det totala antalet defekter.
Jag vill genast notera att vid utvärdering enligt denna formel bör endast de defekter som är relaterade till den bedömda testarens ansvarsområde beaktas. Om flera testare delar ansvaret för en missad defekt, måste den defekten inkluderas i utvärderingen av varje testare. Dessutom tar inte beräkningen hänsyn till lågkritiska defekter.
 Således har vi en parabel av tredje graden, som återspeglar kriteriet för intensiteten av att hitta defekter, som testaren måste uppfylla. I allmänhet, om testarens poäng är över parabeln, betyder det att han fungerar bättre än förväntat, om lägre, så sämre.
Således har vi en parabel av tredje graden, som återspeglar kriteriet för intensiteten av att hitta defekter, som testaren måste uppfylla. I allmänhet, om testarens poäng är över parabeln, betyder det att han fungerar bättre än förväntat, om lägre, så sämre.
Det finns en nyans förknippad med det totala antalet analyserade defekter. Naturligtvis, ju mer statistik, desto bättre, men ibland behöver du analysera de olika stadierna av projektet, ibland behöver du bara en uppskattning för varje tidsperiod. Och det är en sak när 4 defekter hittas under perioden och 2 av dem är av kunden, och en helt annan när 100 defekter hittas, och 50 av dem är av kunden. I båda fallen kommer förhållandet mellan antalet defekter som hittas av kunden och testaren att vara lika med 0,5, men vi förstår att i det första fallet är inte allt så illa, och i det andra är det dags att slå larm.
Efter att utan större framgång ha försökt göra en strikt matematisk bindning till det totala antalet defekter, fäste vi, med samma Irina Lagers ord, "kryckor" till denna formel i form av intervall, för var och en av vilka vi bestämde vår egen koefficienter. Det fanns tre intervall: för statistik från 1 till 20 defekter, från 21 till 60 defekter och för statistik över mer än 60 defekter.
|
Antal defekter |
k |
d |
Uppskattad tillåten del av defekter som hittats av kunden från det totala antalet upptäckta defekter |
Den sista kolumnen i tabellen introducerades för att förklara hur många defekter det är tillåtet för kunden att hitta i detta prov. Följaktligen, ju mindre urvalet är, desto större kan felet vara, och desto fler defekter kan kunden hitta. Ur funktionens synvinkel innebär detta det begränsande minimivärdet på förhållandet mellan antalet defekter som hittas av kunden och testaren, varefter verkningsgraden blir negativ, eller punkten där grafen korsar X-axeln. ju mindre provet är, desto mer rätt bör skärningspunkten med axeln vara. Ledarmässigt betyder detta att ju mindre urvalet är, desto mindre korrekt är en sådan bedömning, därför utgår vi från principen att testare bör utvärderas mindre strikt på ett mindre urval.
Vi har grafer av följande form:

Den svarta grafen återspeglar kriteriet för provtagning av fler än 60 defekter, gult för 21-60 defekter, grönt för provtagning av mindre än 20 defekter. Det kan ses att ju större urvalet är, desto mer till vänster korsar grafen x-axeln. Som redan nämnts, för den utvärderande medarbetaren betyder det att ju större urvalet är, desto mer kan man lita på denna siffra.
Utvärderingsmetoden består i att beräkna effektiviteten av testarens arbete enligt formel (2), med hänsyn till korrigeringsfaktorerna och jämföra denna uppskattning med det erforderliga värdet på grafen. Om poängen är högre än grafen uppfyller testaren förväntningarna, om den är lägre arbetar testaren under den obligatoriska "stapeln". Jag vill också notera att alla dessa siffror valdes empiriskt, och för varje organisation kan de ändras och väljas mer exakt över tid. Därför välkomnar jag bara kommentarer (här eller på min personliga blogg) och förbättringar.
Denna metod för utvärdering av förhållandet mellan antalet defekter som hittats av testteamet och kunden/användaren/klienten förefaller mig rimlig och mer eller mindre objektiv. Det är sant att en sådan bedömning kan utföras först efter projektets slutförande, eller åtminstone om det finns aktiva externa användare av systemet. Men vad händer om produkten inte används ännu? Hur utvärderar man en testares arbete i detta fall?
Dessutom skapar denna teknik för att utvärdera effektiviteten hos en testare flera ytterligare problem:
1. En defekt börjar delas upp i flera mindre.
· Testledaren, som uppmärksammat en sådan situation, bör stoppa den med informella metoder.
2. Defekthantering blir mer komplex på grund av det ökande antalet dubbla poster.
· Regler för att logga defekter till felspårningssystemet, inklusive obligatorisk granskning av liknande defekter, kan hjälpa till att lösa detta problem.
3. Bristande kvalitetsbedömning av de upptäckta defekterna, eftersom testarens enda mål är antalet defekter och, som ett resultat, bristen på motivation för testaren att söka efter "kvalitets"defekter. Ändå kan man inte sätta likhetstecken mellan kritikaliteten och "kvaliteten" hos en defekt, det andra är ett mindre formaliserat koncept.
· Här bör den avgörande rollen spelas av både testarens och chefens ”attityd”. Endast en generell korrekt (!) förståelse av innebörden av en sådan kvantitativ bedömning kan lösa detta problem.
Genom att sammanfatta allt ovan kommer vi till slutsatsen att det inte bara är svårt, utan inte heller helt korrekt att utvärdera en testares arbete endast med antalet upptäckta defekter. Därför bör antalet upptäckta defekter endast vara en av indikatorerna för den integrerade bedömningen av testarens arbete, och inte i dess rena form, utan med hänsyn till de faktorer jag har listat.







