हाल के वर्षों में, सॉफ्टवेयर विकास के क्षेत्र में स्वचालित परीक्षण एक प्रवृत्ति बन गया है, एक अर्थ में, इसका कार्यान्वयन "फैशन के लिए फ़ीड" बन गया है। हालांकि, स्वचालित परीक्षणों का कार्यान्वयन और समर्थन एक बहुत ही संसाधन-गहन और, तदनुसार, महंगी प्रक्रिया है। इस उपकरण के व्यापक उपयोग से अक्सर बिना किसी महत्वपूर्ण परिणाम के महत्वपूर्ण वित्तीय नुकसान होता है।
किसी परियोजना पर ऑटो-परीक्षणों का उपयोग करने की संभावित प्रभावशीलता का मूल्यांकन करने के लिए आप एक काफी सरल उपकरण का उपयोग कैसे कर सकते हैं?
परीक्षण स्वचालन की "दक्षता" के रूप में क्या परिभाषित किया गया है?
दक्षता (मुख्य रूप से आर्थिक) का मूल्यांकन करने का सबसे आम तरीका है निवेश गणना पर वापसी(आरओआई)। लागत और लाभ का अनुपात होने के कारण इसकी गणना काफी सरलता से की जाती है। जैसे ही ROI मान एक से अधिक हो जाता है, समाधान इसमें निवेश किए गए धन को वापस कर देता है और नए लाना शुरू कर देता है।
स्वचालन के मामले में, लाभ का अर्थ है मैन्युअल परीक्षण पर बचत. इसके अलावा, इस मामले में लाभ स्पष्ट नहीं हो सकता है - उदाहरण के लिए, इंजीनियरों द्वारा तदर्थ परीक्षण की प्रक्रिया में दोष खोजने के परिणाम, जिनका समय स्वचालन के कारण मुक्त हो गया था। इस तरह के लाभ की गणना करना काफी कठिन है, इसलिए आप या तो एक धारणा बना सकते हैं (उदाहरण के लिए, + 10%) या इसे छोड़ दें।
हालांकि, स्वचालन को लागू करने का लक्ष्य हमेशा बचत करना नहीं होता है। एक उदाहरण है परीक्षण निष्पादन गति(दोनों एक परीक्षण करने की गति के संदर्भ में, और परीक्षण की आवृत्ति के संदर्भ में)। कई कारणों से, किसी व्यवसाय के लिए परीक्षण की गति महत्वपूर्ण हो सकती है - यदि स्वचालन में निवेश प्राप्त लाभ के साथ भुगतान करता है।
एक और उदाहरण - "मानव कारक" का बहिष्कारसिस्टम परीक्षण प्रक्रिया से। यह महत्वपूर्ण है जब संचालन के निष्पादन की सटीकता और शुद्धता व्यवसाय के लिए महत्वपूर्ण है। इस तरह की त्रुटि की कीमत एक ऑटोटेस्ट को विकसित करने और बनाए रखने की लागत से बहुत अधिक हो सकती है।
प्रदर्शन को क्यों मापें?
दक्षता माप सवालों के जवाब देने में मदद करता है: "क्या यह एक परियोजना पर स्वचालन को लागू करने के लायक है?", "कार्यान्वयन हमें एक महत्वपूर्ण परिणाम कब लाएगा?", "हम कितने घंटे के मैनुअल परीक्षण को बदल देंगे?", "क्या यह संभव है 3 मैन्युअल परीक्षण इंजीनियरों को 1 स्वचालित परीक्षण इंजीनियर से बदलें? और आदि।
ये गणना स्वचालित परीक्षण टीम के लिए लक्ष्य (या मीट्रिक) तैयार करने में मदद कर सकती हैं। उदाहरण के लिए, मैन्युअल परीक्षण के प्रति माह X घंटे की बचत, Y इकाइयों द्वारा परीक्षण टीम की लागत को कम करना।
हर बार जब हम एक और रिलीज को विफल करते हैं, तो यह एक उपद्रव है। दोषी लोग तुरंत प्रकट होते हैं, और अक्सर यह हम, परीक्षक होते हैं। सॉफ़्टवेयर जीवन चक्र में अंतिम कड़ी होना शायद भाग्य है, इसलिए यदि कोई डेवलपर कोड लिखने में बहुत समय व्यतीत करता है, तो कोई यह भी नहीं सोचता कि परीक्षण भी कुछ क्षमताओं वाले लोग हैं।
आप अपने सिर के ऊपर से नहीं कूद सकते, लेकिन आप दिन में 10-12 घंटे काम कर सकते हैं। मैंने ऐसे वाक्यांश बहुत बार सुने हैं)))
जब परीक्षण व्यवसाय की आवश्यकताओं को पूरा नहीं करता है, तो प्रश्न उठता है कि यदि उनके पास समय पर काम करने का समय नहीं है तो परीक्षण क्यों करें। पहले क्या हुआ, आवश्यकताओं को ठीक से क्यों नहीं लिखा गया, आर्किटेक्चर के बारे में क्यों नहीं सोचा गया, कोड को टेढ़ा क्यों किया गया, इस बारे में कोई नहीं सोचता। लेकिन जब आपके पास समय सीमा होती है, और आपके पास परीक्षण पूरा करने का समय नहीं होता है, तो वे तुरंत आपको दंडित करना शुरू कर देते हैं ...
लेकिन यह एक परीक्षक के कठिन जीवन के बारे में कुछ शब्द थे। अब मुद्दे पर
ऐसे कुछ फेकअप के बाद, हर कोई आश्चर्य करने लगता है कि हमारी परीक्षण प्रक्रिया में क्या गलत है। शायद आप, एक नेता के रूप में, आप समस्याओं को समझते हैं, लेकिन आप उन्हें प्रबंधन तक कैसे पहुंचाते हैं? प्रश्न?
प्रबंधन को संख्या, सांख्यिकी की आवश्यकता है। सरल शब्द - उन्होंने आपकी बात सुनी, सिर हिलाया, कहा - "चलो, करो" और बस। उसके बाद, हर कोई आपसे चमत्कार की उम्मीद करता है, लेकिन भले ही आपने कुछ किया हो और वह आपके लिए कारगर न हो, आपको या आपके नेता को फिर से एक टोपी मिलती है।
किसी भी परिवर्तन को प्रबंधन द्वारा समर्थित होना चाहिए, और प्रबंधन को इसका समर्थन करने के लिए, उन्हें संख्या, माप, सांख्यिकी की आवश्यकता होती है।
कई बार मैंने देखा कि कैसे उन्होंने टास्क ट्रैकर्स से विभिन्न आंकड़े अपलोड करने की कोशिश की, यह कहते हुए कि "हम जिरा से मेट्रिक्स हटाते हैं"। लेकिन आइए समझते हैं कि एक मीट्रिक क्या है।
एक मीट्रिक एक तकनीकी या प्रक्रियात्मक रूप से मापने योग्य मान है जो नियंत्रण वस्तु की स्थिति को दर्शाता है।
आइए देखें - स्वीकृति परीक्षण के दौरान हमारी टीम को 50 दोष मिलते हैं। यह बहुत है? या थोड़ा? क्या ये 50 दोष आपको नियंत्रण वस्तु की स्थिति, विशेष रूप से परीक्षण प्रक्रिया के बारे में बताते हैं?
शायद ऩही।
और अगर आपसे कहा जाए कि स्वीकृति परीक्षण के दौरान पाए गए दोषों की संख्या 80% है, जबकि यह केवल 60% होनी चाहिए। मुझे लगता है कि यह तुरंत स्पष्ट है कि बहुत सारे दोष हैं, इसे हल्के ढंग से रखने के लिए, डेवलपर्स का कोड पूरी तरह से जी है ... .. गुणवत्ता के मामले में असंतोषजनक।
कोई कह सकता है कि फिर टेस्टिंग क्यों? लेकिन मैं कहूंगा कि दोष परीक्षण समय है, और परीक्षण समय वह है जो सीधे हमारी समय सीमा को प्रभावित करता है।
इसलिए, हमें सिर्फ मेट्रिक्स की जरूरत नहीं है, हमें केपीआई की जरूरत है।
KPI एक मीट्रिक है जो नियंत्रण वस्तु की स्थिति के संकेतक के रूप में कार्य करता है। एक शर्त लक्ष्य मूल्य और स्थापित सहिष्णुता की उपस्थिति है।
यही है, हमेशा, मेट्रिक्स की एक प्रणाली का निर्माण करते समय, आपके पास एक लक्ष्य और स्वीकार्य विचलन होना चाहिए।
उदाहरण के लिए, आपको (आपका लक्ष्य) चाहिए कि सभी दोषों में से 90% पहले पुनरावृत्ति से हल हो जाएं। साथ ही, आप समझते हैं कि यह हमेशा संभव नहीं होता है, लेकिन भले ही पहली बार हल किए गए दोषों की संख्या 70% हो, यह भी अच्छा है।
यही है, आप अपने लिए एक लक्ष्य और एक स्वीकार्य विचलन निर्धारित करते हैं। अब, यदि आप रिलीज में दोषों की गणना करते हैं और 86% का मान प्राप्त करते हैं, तो यह निश्चित रूप से अच्छा नहीं है, लेकिन अब यह विफलता नहीं है।
गणितीय रूप से यह दिखेगा:
2 सूत्र क्यों? यह इस तथ्य के कारण है कि आरोही और अवरोही मैट्रिक्स की अवधारणा है, अर्थात। जब हमारा लक्ष्य मूल्य 100% या 0% तक पहुंच जाता है।
वे। अगर हम बात कर रहे हैं, उदाहरण के लिए, वाणिज्यिक संचालन में कार्यान्वयन के बाद पाए गए दोषों की संख्या के बारे में, तो कम बेहतर है, और अगर हम परीक्षण मामलों के साथ कार्यक्षमता को कवर करने के बारे में बात कर रहे हैं, तो सबकुछ दूसरी तरफ होगा।
उसी समय, इस या उस मीट्रिक की गणना कैसे करें, इसके बारे में मत भूलना।
प्रतिशत, टुकड़े आदि प्राप्त करने के लिए, हमें प्रत्येक मीट्रिक की गणना करने की आवश्यकता है।
एक उदाहरण के लिए, मैं आपको "परीक्षण द्वारा दोष प्रसंस्करण की समयबद्धता" मीट्रिक के बारे में बताऊंगा।
एक समान दृष्टिकोण का उपयोग करते हुए, जिसका मैंने ऊपर वर्णन किया है, हम लक्ष्य मूल्यों और विचलन के आधार पर मीट्रिक के लिए एक KPI भी बनाते हैं।
चिंता न करें, यह वास्तविक जीवन में उतना कठिन नहीं है जितना चित्र में दिखता है!

हमारे पास क्या है?
खैर, यह तो साफ है कि रिलीज नंबर, घटना संख्या....
क्रिटिकल - ऑड्स। 5,
मेजर - ऑड्स। 3,
मामूली - संभावना। 1.5.
इसके बाद, आपको दोष संसाधन समय के लिए SLA निर्दिष्ट करने की आवश्यकता है। ऐसा करने के लिए, लक्ष्य मान और अधिकतम स्वीकार्य पुन: परीक्षण समय निर्धारित किया जाता है, जैसा कि मैंने मेट्रिक्स की गणना के लिए ऊपर वर्णित किया है।
इन प्रश्नों का उत्तर देने के लिए, हम सीधे प्रदर्शन मीट्रिक पर जाएंगे और सीधे प्रश्न पूछेंगे। और संकेतक की गणना कैसे करें यदि एक अनुरोध का मूल्य "शून्य" के बराबर हो सकता है। यदि एक या एक से अधिक संकेतक शून्य के बराबर हैं, तो अंतिम संकेतक बहुत कम हो जाएगा, इसलिए सवाल उठता है कि हमारी गणना को कैसे संतुलित किया जाए ताकि शून्य मान, उदाहरण के लिए, "1" के गंभीरता कारक के साथ अनुरोध बहुत अधिक न हों। हमारे अंतिम मूल्यांकन को प्रभावित करते हैं।
वज़नकम गंभीरता के साथ अंतिम स्कोर पर अनुरोधों के कम से कम प्रभाव के लिए हमें जिस मूल्य की आवश्यकता होती है, और इसके विपरीत, उच्चतम गंभीरता वाले अनुरोध का स्कोर पर गंभीर प्रभाव पड़ता है, बशर्ते कि हम इस अनुरोध पर अतिदेय हों।
गणना में गलतफहमी न हो, इसके लिए हम गणना के लिए विशिष्ट चर पेश करेंगे:
x दोष का पुन: परीक्षण करने में बिताया गया वास्तविक समय है;
y अधिकतम स्वीकार्य विचलन है;
z गुरुत्वाकर्षण कारक है।
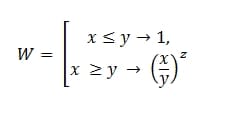
या आम भाषा में, यह है:
डब्ल्यू = ईएसएलआई(एक्स<=y,1,(x/y)^z)
इस प्रकार, भले ही हम अपने द्वारा निर्धारित SLA सीमा से आगे निकल गए हों, हमारे अनुरोध, गंभीरता के आधार पर, हमारे अंतिम स्कोर को गंभीरता से प्रभावित नहीं करेंगे।
ऊपर वर्णित सभी के रूप में:
एक्स- दोष का पुन: परीक्षण करने में बिताया गया वास्तविक समय;
आप- अधिकतम स्वीकार्य विचलन;
जेडगुरुत्वाकर्षण कारक है।
एच- SLA . के अनुसार नियोजित समय
मैं अब यह नहीं जानता कि इसे गणितीय सूत्र में कैसे व्यक्त किया जाए, इसलिए मैं ऑपरेटर के साथ प्रोग्रामिंग भाषा में लिखूंगा यदि।
आर = आईएफ (एक्स<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
नतीजतन, हम पाते हैं कि अगर हम लक्ष्य तक पहुंच गए हैं, तो हमारा अनुरोध मूल्य 1 के बराबर है, अगर हम अनुमेय विचलन से आगे निकल गए, तो रेटिंग शून्य के बराबर है और वजन की गणना की जाती है।
यदि हमारा मूल्य लक्ष्य और अधिकतम स्वीकार्य विचलन के बीच है, तो गंभीरता कारक के आधार पर, हमारा मूल्य सीमा में भिन्न होता है।
अब मैं कुछ उदाहरण दूंगा कि यह हमारे मेट्रिक्स सिस्टम में कैसा दिखेगा।
उनके महत्व (गंभीरता कारक) के आधार पर प्रत्येक अनुरोध का अपना SLA होता है।
हम यहाँ क्या देखते हैं।
पहले अनुरोध में, हम केवल एक घंटे से अपने लक्ष्य मूल्य से विचलित हो गए और पहले से ही 30% की रेटिंग है, जबकि दूसरे अनुरोध में हम केवल एक घंटे से विचलित हो गए हैं, लेकिन संकेतकों का योग अब 30% नहीं है, लेकिन 42.86%। यही है, अनुरोध के अंतिम संकेतक के निर्माण में गंभीरता गुणांक एक महत्वपूर्ण भूमिका निभाते हैं।
उसी समय, तीसरे अनुरोध में, हमने अधिकतम स्वीकार्य समय का उल्लंघन किया और रेटिंग शून्य के बराबर है, लेकिन अनुरोध का वजन बदल गया है, जो हमें अंतिम गुणांक पर इस अनुरोध के प्रभाव की अधिक सही गणना करने की अनुमति देता है।
ठीक है, यह सुनिश्चित करने के लिए, आप बस गणना कर सकते हैं कि संकेतकों का अंकगणितीय माध्य 43.21% के बराबर होगा, और हमें 33.49% मिला, जो उच्च महत्व वाले प्रश्नों के गंभीर प्रभाव को इंगित करता है।
आइए सिस्टम में मानों को 1 घंटे में बदलें।
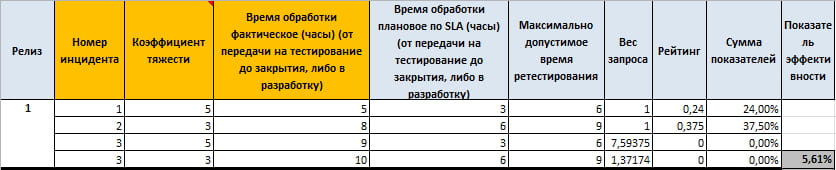
उसी समय, 5 वीं प्राथमिकता के लिए, मूल्य 6% बदल गया, और तीसरे के लिए - 5.36%।
फिर, एक प्रश्न का महत्व उसके स्कोर को प्रभावित करता है।

यही है, हमें मीट्रिक का अंतिम संकेतक मिलता है।
क्या ज़रूरी है!
मैं यह नहीं कह रहा हूं कि मेट्रिक्स सिस्टम का उपयोग मेरे मूल्यों के अनुरूप होना चाहिए, मैं सिर्फ उन्हें बनाए रखने और एकत्र करने के लिए एक दृष्टिकोण का सुझाव दे रहा हूं।
एक संगठन में, मैंने देखा कि उन्होंने HP ALM और JIRA से मीट्रिक एकत्र करने के लिए अपना स्वयं का ढांचा विकसित किया है। वास्तव में यह अच्छा है। लेकिन यह याद रखना महत्वपूर्ण है कि मेट्रिक्स को बनाए रखने की ऐसी प्रक्रिया के लिए नियामक प्रक्रियाओं के गंभीर पालन की आवश्यकता होती है।
ठीक है, और सबसे महत्वपूर्ण बात यह है कि केवल आप ही तय कर सकते हैं कि आप कैसे और कौन से मीट्रिक एकत्र करते हैं। आपको उन मीट्रिक को कॉपी करने की आवश्यकता नहीं है जिन्हें आप एकत्र नहीं कर सकते हैं।
दृष्टिकोण जटिल लेकिन प्रभावी है।
कोशिश करो और शायद तुम भी कर सकते हो!
परफॉर्मेंस लैब के चीफ ऑपरेशंस ऑफिसर अलेक्जेंडर मेशकोव को सॉफ्टवेयर टेस्टिंग, टेस्ट मैनेजमेंट और क्यूए कंसल्टिंग में 5 साल से ज्यादा का अनुभव है। विशेषज्ञ आईएसटीक्यूबी, टीपीआई, टीएमएमआई।
प्रदर्शन मूल्यांकन का लक्ष्य, जिसे कुछ लोग पहले से ही "दुख का सूत्र" कहते हैं, परीक्षक को खुश करना है, ताकि आप संख्याओं के साथ दिखा सकें कि कोई अच्छा काम करता है, और इसके लिए आपको उसे सिर पर थपथपाना होगा, और अन्य खराब है - और आपको उसे कोड़े मारने की जरूरत है ... केवल इस मानदंड के अनुसार मूल्यांकन केवल एक ही नहीं हो सकता है, इसलिए, इसे अन्य संकेतकों के साथ संयोजन में माना जाना चाहिए, जैसे कि योजना का कार्यान्वयन, परीक्षण स्वचालन, आदि।
किसी अन्य कर्मचारी की तरह एक परीक्षक के प्रदर्शन को परिमाणित किया जाना चाहिए, अर्थात। एक मापने योग्य संकेतक में। लेकिन कौन से संकेतक चुनना है?
पहली बात जो दिमाग में आती है वह है दोषों की संख्या। और यह वह संकेतक था जिसे मैंने तुरंत इनरेको लैन में पेश करने की कोशिश की। हालांकि, तुरंत एक गर्म चर्चा हुई, जिसने मुझे इस मानदंड का विश्लेषण करने के लिए प्रेरित किया। इस विषय पर, मैं इस लेख में चर्चा करना चाहता हूं।
पाए गए दोषों की संख्या एक अत्यंत फिसलन संकेतक है। इस समस्या पर चर्चा करने वाले नेटवर्क के सभी संसाधन भी इसे दोहराते हैं (http://www.software-testing.ru/, blogs.msdn.com/imtesty, it4business.ru, sqadotby.blogspot.com, blogs.msdn.com / larryosterman , sql.ru , http://www.testingperspective.com/ और कई, कई अन्य)। अपने स्वयं के अनुभव और इन संसाधनों का विश्लेषण करने के बाद, मैं समस्याओं के निम्नलिखित वृक्ष पर आया:
सबसे पहले, दोष से दोष - कलह। एक परीक्षक किसी एप्लिकेशन में बटनों के स्थान में दोषों की तलाश कर सकता है, दूसरा तर्क में तल्लीन कर सकता है और जटिल परीक्षण स्थितियों के साथ आ सकता है। ज्यादातर मामलों में, पहले परीक्षक को अधिक दोष मिलेंगे, क्योंकि परीक्षण की तैयारी में भी उसे बहुत कम समय लगेगा, लेकिन ऐसे दोषों का मूल्य बहुत कम है। दोष की गंभीरता का परिचय देकर इस समस्या को आसानी से हल किया जाता है। इसका मूल्यांकन प्रत्येक श्रेणी में पाए जाने वाले दोषों की संख्या से किया जा सकता है। उदाहरण के लिए, हमारे पास उनमें से 4 हैं: महत्वपूर्ण, महत्वपूर्ण, मध्यम और महत्वहीन। लेकिन चूंकि आलोचनात्मकता की परिभाषा पूरी तरह से स्पष्ट नहीं है, हालांकि हमारे पास आलोचनात्मकता के औपचारिक संकेत हैं, हम दो और विश्वसनीय तरीके अपना सकते हैं। पहला यह है कि चयनित अवधि के दौरान पाए जाने वाले दोषों का एक निश्चित हिस्सा गैर-महत्वपूर्ण दोष होना चाहिए। दूसरा आकलन में मामूली खामियों को ध्यान में नहीं रखना है। इस प्रकार, हम छोटी-मोटी खामियों का वर्णन करने की कीमत पर अधिक से अधिक दोषों को स्कोर करने के लिए परीक्षक की इच्छा के खिलाफ लड़ते हैं, उसे (या अधिक बार उसे) गहरी खुदाई करने और गंभीर दोषों को खोजने के लिए मजबूर करते हैं। और वे हमेशा हैं, मेरे अनुभव पर विश्वास करें। मैंने दूसरा विकल्प चुना - मामूली दोषों को त्यागें।
इस तरह के मानदंड के "फिसलन" का दूसरा कारण सिस्टम में पर्याप्त संख्या में दोषों की उपस्थिति है ताकि परीक्षक उन्हें ढूंढ सकें। यहां तीन कारक हैं। पहली प्रणाली के तर्क और प्रौद्योगिकी की जटिलता है। दूसरा कोडिंग की गुणवत्ता है। और तीसरा प्रोजेक्ट स्टेज है। आइए इन तीन कारकों को क्रम में लें। तर्क और तकनीक की जटिलता जिस पर सिस्टम लिखा गया है, संभावित दोषों को प्रभावित करता है जिन्हें बनाया जा सकता है। इसके अलावा, यहां निर्भरता प्रत्यक्ष से बहुत दूर है। यदि आप एक जटिल या अपरिचित मंच पर सरल तर्क लागू करते हैं, तो त्रुटियां मुख्य रूप से कार्यान्वयन तकनीक के गलत उपयोग से संबंधित होंगी। यदि आप एक आदिम मंच पर जटिल तर्क को लागू करते हैं, तो, सबसे अधिक संभावना है, त्रुटियों को तर्क के साथ और इस तरह के तर्क को एक आदिम भाषा में लागू करने की जटिलता के साथ जोड़ा जाएगा। यानी सिस्टम को लागू करने के लिए तकनीक चुनते समय संतुलन की जरूरत होती है। लेकिन अक्सर तकनीक ग्राहक या बाजार द्वारा तय की जाती है, इसलिए हम शायद ही प्रभावित कर सकें। इसलिए, दोषों की संभावित संख्या के एक निश्चित गुणांक के रूप में इस कारक को ध्यान में रखना ही शेष है। इसके अलावा, इस गुणांक का मूल्य, सबसे अधिक संभावना है, एक विशेषज्ञ द्वारा निर्धारित किया जाना चाहिए।
एन्कोडिंग गुणवत्ता। यहां हम निश्चित रूप से किसी भी तरह से डेवलपर को प्रभावित नहीं कर सकते। लेकिन हम कर सकते हैं: ए) फिर से, डेवलपर के स्तर का विशेषज्ञ रूप से मूल्यांकन करें और इसे एक अन्य कारक के रूप में शामिल करें, और बी) यूनिट परीक्षणों के माध्यम से कोड में त्रुटियों की उपस्थिति को रोकने की कोशिश करें, यूनिट परीक्षणों के साथ 100% कोड कवरेज एक अनिवार्य आवश्यकता है। .
परियोजना चरण। यह लंबे समय से ज्ञात है कि सभी दोषों को खोजना असंभव है, सिवाय शायद एक तुच्छ कार्यक्रम या संयोग से, क्योंकि पूर्णता की कोई सीमा नहीं है, और पूर्णता के साथ किसी भी विसंगति को एक दोष माना जा सकता है। लेकिन यह एक बात है जब कोई परियोजना सक्रिय विकास चरण में होती है, और जब यह समर्थन चरण में होती है तो बिल्कुल दूसरी होती है। और अगर हम सिस्टम जटिलता और प्रौद्योगिकी और कोडिंग गुणवत्ता के कारकों को भी ध्यान में रखते हैं, तो यह स्पष्ट है कि यह सब उन दोषों की संख्या को मौलिक रूप से प्रभावित करता है जो एक परीक्षक खोजने में सक्षम है। जैसे-जैसे परियोजना पूर्णता या समर्थन चरण के करीब पहुंचती है (हम इसे सशर्त कहते हैं और इसे सहज रूप से परिभाषित करते हैं), सिस्टम में दोषों की संख्या कम हो जाती है, और इसलिए दोषों की संख्या भी पाई जाती है। और यहां उस क्षण को निर्धारित करना आवश्यक है जब एक निश्चित संख्या में दोषों को खोजने के लिए परीक्षक की आवश्यकता के लिए अनुचित हो जाता है। ऐसे क्षण को निर्धारित करने के लिए, यह जानना अच्छा होगा कि कुल दोषों की संख्या का कितना अंश हम खोजने में सक्षम हैं और प्रणाली में अभी भी कितने दोष शेष हैं। यह एक अलग चर्चा का विषय है, लेकिन एक काफी सरल और प्रभावी सांख्यिकीय पद्धति लागू की जा सकती है।
पिछली परियोजनाओं के आंकड़ों के आधार पर, यह समझना संभव है कि एक निश्चित त्रुटि के साथ, सिस्टम में कितने दोष थे और परीक्षण टीम द्वारा परियोजना के विभिन्न अवधियों में कितने पाए गए थे। इस प्रकार, आप परीक्षण टीम की प्रभावशीलता का एक निश्चित औसत संकेतक प्राप्त कर सकते हैं। इसे प्रत्येक व्यक्तिगत परीक्षक के लिए विघटित किया जा सकता है और व्यक्तिगत मूल्यांकन प्राप्त किया जा सकता है। जितना अधिक अनुभव और आँकड़े होंगे, त्रुटि उतनी ही कम होगी। आप "एरर सीडिंग" पद्धति का भी उपयोग कर सकते हैं, जब हम जानते हैं कि सिस्टम में कितनी त्रुटियां हैं। स्वाभाविक रूप से, अतिरिक्त कारकों को ध्यान में रखा जाना चाहिए, जैसे कि सिस्टम का प्रकार, तर्क की जटिलता, मंच, और इसी तरह। तो, हम परियोजना के चरण और पाए गए दोषों के प्रतिशत के बीच संबंध प्राप्त करते हैं। अब हम इस निर्भरता को विपरीत दिशा में लागू कर सकते हैं: पाए गए दोषों की संख्या और परियोजना के वर्तमान चरण को जानकर, हम अपने सिस्टम में दोषों की कुल संख्या (निश्चित रूप से कुछ त्रुटि के साथ) निर्धारित कर सकते हैं। और फिर, व्यक्तिगत या समग्र मूल्यांकन के संकेतकों के आधार पर, आप यह निर्धारित कर सकते हैं कि एक परीक्षक या एक टीम शेष समयावधि में कितने दोषों का पता लगाने में सक्षम है। इस मूल्यांकन के आधार पर, परीक्षक की प्रभावशीलता के लिए मानदंड निर्धारित करना पहले से ही संभव है।
परीक्षक प्रदर्शन संकेतक फ़ंक्शन इस तरह दिख सकता है:
दोष के- पाए गए दोषों की संख्या,
तीव्रता- पाए गए दोषों की गंभीरता,
जटिलता- सिस्टम लॉजिक की जटिलता,
प्लैटफ़ॉर्म- सिस्टम कार्यान्वयन मंच,
अवस्था- परियोजना का चरण,
अवधिविचाराधीन समयावधि है।
लेकिन पहले से ही एक विशिष्ट मानदंड जिसे एक परीक्षक को पूरा करना चाहिए, उसे अनुभवजन्य रूप से चुना जाना चाहिए और किसी विशेष संगठन की बारीकियों को ध्यान में रखना चाहिए।
फिलहाल सभी कारकों को ध्यान में रखना संभव नहीं है, हालांकि, हमारे प्रमुख डेवलपर इवान एस्टाफिव और प्रोजेक्ट मैनेजर इरिना लेगर के साथ, हम निम्नलिखित सूत्र के साथ आए हैं जो दोषों की संख्या और उनकी आलोचनात्मकता को ध्यान में रखते हैं:
 , कहाँ पे
, कहाँ पे
इ- दक्षता, पाए गए दोषों की संख्या से निर्धारित होती है,
डी ग्राहक- ग्राहक द्वारा पाए गए दोषों की संख्या, लेकिन जो मूल्यांकन परीक्षक को मिलनी चाहिए थी,
डी परीक्षक- परीक्षक द्वारा पाए गए दोषों की संख्या,
कतथा डी- दोषों की कुल संख्या के लिए सुधार कारक।
मैं तुरंत नोट करना चाहता हूं कि इस सूत्र के अनुसार मूल्यांकन करते समय, केवल उन दोषों को ध्यान में रखा जाना चाहिए जो मूल्यांकन किए गए परीक्षक की जिम्मेदारी के क्षेत्र से संबंधित हैं। यदि एक से अधिक परीक्षक चूके हुए दोष के लिए जिम्मेदारी साझा करते हैं, तो उस दोष को प्रत्येक परीक्षक के मूल्यांकन में शामिल किया जाना चाहिए। साथ ही, गणना कम-महत्वपूर्ण दोषों को ध्यान में नहीं रखती है।
 इस प्रकार, हमारे पास तीसरी डिग्री का एक परवलय है, जो दोषों को खोजने की तीव्रता के मानदंड को दर्शाता है, जिसे परीक्षक को पूरा करना होगा। सामान्य तौर पर, यदि परीक्षक का स्कोर परवलय से ऊपर है, तो इसका मतलब है कि वह अपेक्षा से बेहतर काम करता है, यदि कम है, तो, तदनुसार, बदतर।
इस प्रकार, हमारे पास तीसरी डिग्री का एक परवलय है, जो दोषों को खोजने की तीव्रता के मानदंड को दर्शाता है, जिसे परीक्षक को पूरा करना होगा। सामान्य तौर पर, यदि परीक्षक का स्कोर परवलय से ऊपर है, तो इसका मतलब है कि वह अपेक्षा से बेहतर काम करता है, यदि कम है, तो, तदनुसार, बदतर।
विश्लेषण किए गए दोषों की कुल संख्या से जुड़ी एक बारीकियां है। स्वाभाविक रूप से, अधिक आँकड़े, बेहतर, लेकिन कभी-कभी आपको परियोजना के विभिन्न चरणों का विश्लेषण करने की आवश्यकता होती है, कभी-कभी आपको प्रत्येक अवधि के लिए केवल एक अनुमान की आवश्यकता होती है। और यह एक बात है जब अवधि के दौरान 4 दोष पाए जाते हैं और उनमें से 2 ग्राहक द्वारा होते हैं, और एक और जब 100 दोष पाए जाते हैं, और उनमें से 50 ग्राहक द्वारा होते हैं। दोनों ही मामलों में, ग्राहक और परीक्षक द्वारा पाए गए दोषों की संख्या का अनुपात 0.5 के बराबर होगा, लेकिन हम समझते हैं कि पहले मामले में, सब कुछ इतना बुरा नहीं है, लेकिन दूसरे में अलार्म बजने का समय है।
दोषों की कुल संख्या के लिए एक सख्त गणितीय बंधन बनाने के लिए बहुत अधिक सफलता के बिना, हमने उसी इरिना लेगर के शब्दों में, अंतराल के रूप में इस सूत्र को "बैसाखी" संलग्न किया, जिनमें से प्रत्येक के लिए हमने अपना स्वयं का निर्धारण किया गुणांक। तीन अंतराल थे: आँकड़ों के लिए 1 से 20 दोषों के लिए, 21 से 60 दोषों के लिए, और 60 से अधिक दोषों के आंकड़ों के लिए।
|
दोषों की संख्या |
क |
डी |
पाए गए दोषों की कुल संख्या से ग्राहक द्वारा पाए गए दोषों का अनुमानित स्वीकार्य भाग |
तालिका में अंतिम कॉलम को यह समझाने के लिए पेश किया गया था कि ग्राहक को इस नमूने में कितने दोष खोजने की अनुमति है। तदनुसार, नमूना जितना छोटा होगा, त्रुटि उतनी ही अधिक हो सकती है, और ग्राहक द्वारा अधिक दोष पाए जा सकते हैं। फ़ंक्शन के दृष्टिकोण से, इसका मतलब ग्राहक और परीक्षक द्वारा पाए गए दोषों की संख्या के अनुपात के न्यूनतम मूल्य को सीमित करना है, जिसके बाद दक्षता नकारात्मक हो जाती है, या वह बिंदु जहां ग्राफ एक्स अक्ष को पार करता है। नमूना जितना छोटा होगा, अक्ष के साथ प्रतिच्छेदन उतना ही अधिक सही होना चाहिए। प्रबंधकीय शब्दों में, इसका मतलब है कि नमूना जितना छोटा होगा, ऐसा आकलन उतना ही कम सटीक होगा, इसलिए, हम इस सिद्धांत से आगे बढ़ते हैं कि छोटे नमूने पर परीक्षकों का कम सख्ती से मूल्यांकन किया जाना चाहिए।
हमारे पास निम्नलिखित फॉर्म के ग्राफ हैं:

काला ग्राफ 60 से अधिक दोषों के नमूने के लिए मानदंड को दर्शाता है, 21-60 दोषों के लिए पीला, 20 से कम दोषों के नमूने के लिए हरा। यह देखा जा सकता है कि जितना बड़ा नमूना, उतना ही बाईं ओर ग्राफ एक्स-अक्ष को पार करता है। जैसा कि पहले ही उल्लेख किया गया है, मूल्यांकन करने वाले कर्मचारी के लिए, इसका मतलब है कि नमूना जितना बड़ा होगा, उतना ही आप इस आंकड़े पर भरोसा कर सकते हैं।
मूल्यांकन पद्धति में सूत्र (2) के अनुसार परीक्षक के काम की प्रभावशीलता की गणना करना, सुधार कारकों को ध्यान में रखना और इस अनुमान की तुलना ग्राफ पर आवश्यक मूल्य के साथ करना शामिल है। यदि स्कोर ग्राफ़ से अधिक है, तो परीक्षक अपेक्षाओं को पूरा करता है; यदि यह कम है, तो परीक्षक आवश्यक "बार" के नीचे काम करता है। मैं यह भी नोट करना चाहता हूं कि इन सभी आंकड़ों को अनुभवजन्य रूप से चुना गया था, और प्रत्येक संगठन के लिए उन्हें बदला जा सकता है और समय के साथ अधिक सटीक रूप से चुना जा सकता है। इसलिए, किसी भी टिप्पणी (यहां या मेरे व्यक्तिगत ब्लॉग पर) और सुधार, मैं केवल स्वागत करता हूं।
परीक्षण टीम और ग्राहक / उपयोगकर्ता / ग्राहक द्वारा पाई गई दोषों की संख्या के अनुपात से मूल्यांकन की यह विधि मुझे उचित और कमोबेश उद्देश्यपूर्ण लगती है। सच है, ऐसा मूल्यांकन परियोजना के पूरा होने के बाद ही किया जा सकता है, या, कम से कम, अगर सिस्टम के सक्रिय बाहरी उपयोगकर्ता हैं। लेकिन क्या होगा अगर उत्पाद अभी तक उपयोग में नहीं है? इस मामले में एक परीक्षक के काम का मूल्यांकन कैसे करें?
इसके अलावा, एक परीक्षक की प्रभावशीलता के मूल्यांकन के लिए यह तकनीक कई अतिरिक्त समस्याएं पैदा करती है:
1. एक दोष कई छोटे में विभाजित होने लगता है।
· ऐसी स्थिति पर ध्यान देने वाले परीक्षण प्रबंधक को अनौपचारिक तरीकों से इसे रोकना चाहिए।
2. डुप्लिकेट प्रविष्टियों की बढ़ती संख्या के कारण दोष प्रबंधन अधिक जटिल हो जाता है।
· बग ट्रैकिंग सिस्टम में दोषों को दर्ज करने के नियम, समान दोषों की अनिवार्य समीक्षा सहित, इस समस्या को हल करने में मदद कर सकते हैं।
3. पाए गए दोषों के गुणवत्ता मूल्यांकन का अभाव, क्योंकि परीक्षक का एकमात्र लक्ष्य दोषों की संख्या है, और परिणामस्वरूप, परीक्षक के लिए "गुणवत्ता" दोषों की खोज करने के लिए प्रेरणा की कमी है। फिर भी, कोई एक दोष की गंभीरता और "गुणवत्ता" की बराबरी नहीं कर सकता है, दूसरा एक कम औपचारिक अवधारणा है।
· यहां निर्णायक भूमिका परीक्षक और प्रबंधक दोनों के "रवैये" द्वारा निभाई जानी चाहिए। इस तरह के मात्रात्मक मूल्यांकन के अर्थ की केवल एक सामान्य सही (!) समझ ही इस समस्या को हल कर सकती है।
उपरोक्त सभी को सारांशित करते हुए, हम इस निष्कर्ष पर आते हैं कि यह न केवल कठिन है, बल्कि केवल पाए गए दोषों की संख्या से एक परीक्षक के काम का मूल्यांकन करना पूरी तरह से सही नहीं है। इसलिए, पाए गए दोषों की संख्या परीक्षक के काम के अभिन्न मूल्यांकन के संकेतकों में से एक होनी चाहिए, न कि अपने शुद्ध रूप में, बल्कि मेरे द्वारा सूचीबद्ध कारकों को ध्यान में रखते हुए।







