През последните години автоматизираното тестване се превърна в тенденция в областта на разработката на софтуер, в известен смисъл неговото прилагане се превърна в „хранене на модата“. Внедряването и поддръжката на автоматизирани тестове обаче е много ресурсоемка и съответно скъпа процедура. Широкото използване на този инструмент най-често води до значителни финансови загуби без значителен резултат.
Как можете да използвате доста прост инструмент, за да оцените възможната ефективност от използването на автотестове в проект?
Какво се определя като "ефективност" на автоматизацията на тестовете?
Най-разпространеният начин за оценка на ефективността (предимно икономически) е изчисляване на възвръщаемостта на инвестицията(ROI). Изчислява се доста просто, като е съотношението на печалбата към разходите. Веднага щом стойността на ROI надхвърли единица, решението връща инвестираните в него средства и започва да носи нови.
В случай на автоматизация, печалба означава спестявания от ръчно тестване. Освен това печалбата в този случай може да не е очевидна - например резултатите от откриването на дефекти в процеса на ad-hoc тестване от инженери, чието време беше освободено поради автоматизация. Такава печалба е доста трудна за изчисляване, така че можете да направите предположение (например + 10%) или да го пропуснете.
Въпреки това, спестяването не винаги е целта на внедряването на автоматизация. Един пример е скорост на изпълнение на теста(както по отношение на скоростта на извършване на един тест, така и по отношение на честотата на тестване). Поради редица причини скоростта на тестване може да бъде критична за бизнеса - ако инвестициите в автоматизация се изплащат с получената печалба.
Друг пример - изключване на "човешкия фактор"от процеса на тестване на системата. Това е важно, когато точността и коректността на изпълнението на операциите са от решаващо значение за бизнеса. Цената на такава грешка може да бъде много по-висока от цената за разработване и поддържане на автотест.
Защо измервате производителността?
Измерването на ефективността помага да се отговори на въпросите: „Струва ли си да се внедри автоматизация в даден проект?“, „Кога внедряването ще ни донесе значителен резултат?“, „Колко часа ръчно тестване ще заменим?“, „Възможно ли е да да замени 3 инженери за ръчно тестване с 1 инженер по автоматизирано тестване? и т.н.
Тези изчисления могат да помогнат за формулирането на цели (или показатели) за екипа за автоматизирано тестване. Например спестяване на X часа на месец ръчно тестване, намаляване на разходите на екипа за тестване с Y единици.
Всеки път, когато провалим поредното издание, това е суетене. Веднага се появяват виновни хора и често това сме ние, тестерите. Вероятно е съдбата да бъде последното звено в жизнения цикъл на софтуера, така че дори разработчикът да прекарва много време в писане на код, никой дори не мисли, че тестването също е хора с определени възможности.
Не можете да скачате над главата си, но можете да работите по 10-12 часа на ден. Много често чух такива фрази)))
Когато тестването не отговаря на нуждите на бизнеса, тогава възниква въпросът защо изобщо да тестват, ако нямат време да работят навреме. Никой не се замисля какво се е случило преди, защо изискванията не са написани както трябва, защо архитектурата не е измислена, защо кодът е крив. Но когато имате краен срок и нямате време да завършите тестването, те веднага започват да ви наказват ...
Но това бяха няколко думи за трудния живот на тестер. Сега към въпроса 🙂
След няколко такива фалшификации всеки започва да се чуди какво не е наред в нашия процес на тестване. Може би вие като лидер разбирате проблемите, но как ги предавате на ръководството? Въпрос?
Ръководството има нужда от цифри, статистика. Прости думи – послушаха те, кимнаха с глави, казаха – „Хайде, направи го“ и готово. След това всички очакват чудо от вас, но дори и да сте направили нещо и то не се е получило за вас, вие или вашият лидер отново получавате шапка.
Всяка промяна трябва да бъде подкрепена от ръководството, а за да я поддържа, те се нуждаят от числа, измервания, статистика.
Много пъти виждах как се опитват да качат различни статистически данни от тракерите на задачи, казвайки, че „Ние премахваме показатели от JIRA“. Но нека разберем какво е метрика.
Показателят е технически или процедурно измерима стойност, която характеризира състоянието на контролния обект.
Да видим - нашият екип открива 50 дефекта по време на приемно тестване. Много е? Или малко? Тези 50 дефекта казват ли ви за състоянието на контролния обект, по-специално за процеса на тестване?
Вероятно не.
И ако ви беше казано, че броят на дефектите, открити по време на тестовете за приемане, е 80%, докато трябва да бъде само 60%. Мисля, че веднага става ясно, че има много дефекти, съответно, меко казано, кодът на разработчиците е напълно г ... .. незадоволителен по отношение на качеството.
Някой може ли да каже, че защо тогава тестване? Но ще кажа, че дефектите са време за тестване, а времето за тестване е това, което пряко засяга нашия срок.
Следователно, ние се нуждаем не само от показатели, имаме нужда от KPI.
KPI е показател, който служи като индикатор за състоянието на контролния обект. Предпоставка е наличието на целева стойност и установени толеранси.
Тоест винаги при изграждането на система от метрики трябва да имате цел и допустими отклонения.
Например, имате нужда (вашата цел) 90% от всички дефекти да бъдат решени от първата итерация. В същото време разбирате, че това не винаги е възможно, но дори ако броят на дефектите, отстранени за първи път, е 70%, това също е добре.
Тоест вие си поставяте цел и приемливо отклонение. Сега, ако преброите дефектите в изданието и получите стойност от 86%, тогава това със сигурност не е добре, но вече не е провал.
Математически ще изглежда така:
Защо 2 формули? Това се дължи на факта, че има концепция за възходяща и низходяща метрика, т.е. когато нашата целева стойност се доближи до 100% или 0%.
Тези. ако говорим например за броя на дефектите, открити след внедряване в търговска експлоатация, тогава колкото по-малко, толкова по-добре, а ако говорим за покриване на функционалността с тестови случаи, тогава всичко ще бъде обратното.
В същото време не забравяйте как да изчислите този или онзи показател.
За да получим нужните проценти, парчета и т.н., трябва да изчислим всеки показател.
За илюстративен пример ще ви разкажа за метриката „Своевременност на обработка на дефекта чрез тестване“.
Използвайки подобен подход, който описах по-горе, ние също формираме KPI за метриката въз основа на целевите стойности и отклонения.
Не се притеснявайте, в реалния живот не е толкова трудно, колкото изглежда на снимката!

какво имаме?
Е, ясно е, че номерът на изданието, номерът на инцидента ....
Критичен - шансове. пет,
Основни - коефициенти. 3,
Малък - коефициенти. 1.5.
След това трябва да посочите SLA за времето за обработка на дефекта. За да направите това, се определят целевата стойност и максималното допустимо време за повторно тестване, подобно на начина, по който го описах по-горе за изчисляване на показателите.
За да отговорим на тези въпроси, ще преминем направо към показателите за ефективност и ще зададем въпроса веднага. И как да изчислим индикатора, ако стойността на една заявка може да бъде равна на „нула“. Ако един или повече индикатори са равни на нула, тогава крайният индикатор ще намалее много, така че възниква въпросът как да балансираме нашето изчисление, така че нулевите стойности, например на заявки с коефициент на сериозност „1“, да не са много влияят на крайната ни оценка.
Теглое стойността, от която се нуждаем, за да окажем най-малко влияние на заявките върху крайния резултат с ниска тежест, и обратно, заявка с най-висока сериозност има сериозно влияние върху резултата, при условие че сме просрочени по тази заявка.
За да нямате неразбиране в изчисленията, ще въведем конкретни променливи за изчислението:
x е действителното време, прекарано за повторно тестване на дефекта;
y е максимално допустимото отклонение;
z е гравитационният фактор.
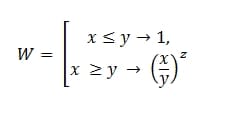
Или на общ език, това е:
W=ESLI(х<=y,1,(x/y)^z)
По този начин, дори и да надхвърлим ограниченията на SLA, които сме поставили, нашето искане, в зависимост от тежестта, няма да повлияе сериозно на крайния ни резултат.
Всичко както е описано по-горе:
х– реално време, прекарано за повторно тестване на дефекта;
г– максимално допустимото отклонение;
zе гравитационният фактор.
ч-планирано време според SLA
Вече не знам как да изразя това с математическа формула, така че ще пиша на език за програмиране с оператора АКО
R = IF(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
В резултат на това получаваме, че ако сме достигнали целта, тогава стойността на нашата заявка е равна на 1, ако сме надхвърлили допустимото отклонение, тогава рейтингът е равен на нула и се изчисляват теглата.
Ако нашата стойност е между целта и максимално допустимото отклонение, тогава в зависимост от фактора на сериозност нашата стойност варира в диапазона .
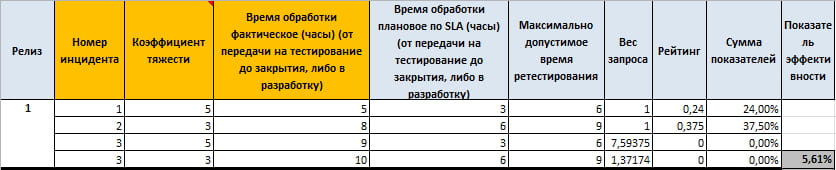
Сега ще дам няколко примера как ще изглежда в нашата метрична система.
Всяка заявка има свой собствен SLA в зависимост от тяхната важност (коефициент на сериозност).
Какво виждаме тук.
При първата заявка се отклонихме от целевата си стойност само с един час и вече имаме рейтинг от 30%, докато във втората заявка също се отклонихме само с един час, но сборът от показателите вече не е 30%, а 42,86%. Тоест коефициентите на тежест играят важна роля при формирането на крайния индикатор на заявката.
В същото време в третото искане нарушихме максимално допустимото време и рейтингът е равен на нула, но тежестта на заявката се промени, което ни позволява по-правилно да изчислим въздействието на това искане върху крайния коефициент.
Е, за да се уверите в това, можете просто да изчислите, че средноаритметичната стойност на индикаторите ще бъде равна на 43,21%, а ние получихме 33,49%, което показва сериозно въздействие на заявки с голяма важност.
Нека променим стойностите в системата на 1 час.
в същото време за 5-ия приоритет стойността се променя с 6%, а за третия - с 5,36%.
Отново, важността на заявката влияе върху нейния резултат.

Това е всичко, получаваме крайния индикатор на метриката.
Какво е важно!
Не казвам, че използването на метричната система трябва да става по аналогия с моите ценности, просто предлагам подход за поддържането и събирането им.
В една организация видях, че са разработили своя собствена рамка за събиране на показатели от HP ALM и JIRA. Наистина е яко. Но е важно да запомните, че такъв процес на поддържане на показатели изисква сериозно придържане към регулаторните процеси.
Е, и най-важното, само вие можете да решите как и какви показатели да събирате. Не е нужно да копирате тези показатели, които не можете да съберете.
Подходът е сложен, но ефективен.
Опитайте и може би и вие можете!
Александър Мешков, главен оперативен директор в Performance Lab, има над 5 години опит в тестването на софтуер, управлението на тестове и QA консултирането. Експерт ISTQB, TPI, TMMI.
Целта на оценката на ефективността, която някои вече нарекоха „формулата за нещастие“, е просто да направи тестера щастлив, така че да покажете с числа, че единият работи добре и трябва да бъде потупан по главата за него, а другият е лош и трябва да се напляска ... Оценката само по този критерий не може да бъде единствената, следователно трябва да се разглежда във връзка с други показатели, като изпълнение на плана, автоматизация на теста и т.н.
Работата на тестер, както и всеки друг служител, трябва да бъде количествено измерена, т.е. в измерим показател. Но кои индикатори да изберете?
Първото нещо, което идва на ум, е броят на откритите дефекти. И точно този индикатор веднага се опитах да въведа в Inreco LAN. Веднага обаче възникна разгорещена дискусия, която ме подтикна да анализирам този критерий. По тази тема искам да обсъдя в тази статия.
Броят на откритите дефекти е изключително хлъзгав индикатор. Всички ресурси в мрежата, обсъждащи този проблем, също повтарят това (http://www.software-testing.ru/, blogs.msdn.com/imtesty, it4business.ru, sqadotby.blogspot.com, blogs.msdn.com / larryosterman, sql.ru, http://www.testingperspective.com/ и много, много други). След като анализирах собствения си опит и тези ресурси, стигнах до следното дърво от проблеми:
Първо, дефект към дефект - раздор. Един тестер може да търси дефекти в местоположението на бутоните в дадено приложение, друг може да се задълбочи в логиката и да измисли сложни тестови ситуации. В повечето случаи първият тестер ще открие повече дефекти, тъй като дори подготовката на теста ще му отнеме много по-малко време, но стойността на такива дефекти е много по-ниска. Този проблем лесно се решава чрез въвеждане на критичността на дефекта. Може да се оцени по броя на откритите дефекти във всяка от категориите. Например имаме 4 от тях: критични, значими, средни и незначителни. Но тъй като определението за критичност не е съвсем ясно, въпреки че имаме формални признаци на критичност, можем да отидем по два по-надеждни пътя. Първият е, че определена част от дефектите, открити през избрания период, трябва да са некритични дефекти. Второто е да не се вземат предвид дребните дефекти в оценката. Така ние се борим срещу желанието на тестера да отбележи възможно най-много дефекти за сметка на описването на дребни недостатъци, принуждавайки го (или по-често нея) да копае по-дълбоко и да открие сериозни дефекти. И те винаги са, повярвайте на моя опит. Избрах втория вариант - изхвърлете дребните дефекти.
Втората причина за „хлъзгавостта“ на такъв критерий е наличието на достатъчен брой дефекти в системата, така че тестерът да може да ги намери. Тук има три фактора. Първият е сложността на логиката и технологията на системата. Второто е качеството на кодирането. И третият е етапът на проекта. Нека вземем тези три фактора по ред. Сложността на логиката и технологията, върху които е написана системата, влияе върху потенциалните недостатъци, които могат да бъдат направени. Освен това зависимостта тук далеч не е пряка. Ако внедрите проста логика на сложна или непозната платформа, тогава грешките ще бъдат свързани основно с неправилно използване на технологията за внедряване. Ако внедрите сложна логика на примитивна платформа, тогава най-вероятно грешките ще бъдат свързани както със самата логика, така и със сложността на внедряването на такава логика на примитивен език. Тоест е необходим баланс при избора на технология за внедряване на системата. Но често технологията се диктува от клиента или от пазара, така че трудно можем да повлияем. Следователно остава само да се вземе предвид този фактор като определен коефициент на потенциалния брой дефекти. Освен това стойността на този коефициент най-вероятно трябва да бъде определена от експерт.
Качество на кодиране. Тук определено не можем да повлияем на разработчика по никакъв начин. Но ние можем: а) отново експертно да оценим нивото на разработчика и да го включим като друг фактор и б) да се опитаме да предотвратим появата на грешки в кода чрез модулни тестове, като направим 100% покритие на кода с модулни тестове задължително изискване .
Етап на проекта. Отдавна е известно, че е невъзможно да се намерят всички дефекти, освен може би за тривиална програма или случайно, тъй като няма граница на съвършенството и всяко несъответствие със съвършенството може да се счита за дефект. Но едно е, когато проектът е в активна фаза на разработка, и съвсем друго, когато е във фаза на поддръжка. И ако вземем предвид и факторите на сложността на системата и технологията и качеството на кодирането, става ясно, че всичко това коренно влияе върху броя на дефектите, които един тестер е в състояние да открие. С наближаването на проекта към завършване или фазата на поддръжка (наричаме всичко това условно и сега го дефинираме интуитивно), броят на дефектите в системата намалява, а оттам и броят на откритите дефекти. И тук е необходимо да се определи момента, в който става неразумно да се изисква от тестера да открие определен брой дефекти. За да определим такъв момент, би било хубаво да знаем каква част от общия брой дефекти сме в състояние да открием и колко дефекти все още са останали в системата. Това е тема за отделна дискусия, но може да се приложи един доста прост и ефективен статистически метод.
Въз основа на статистиката на предишни проекти е възможно с известна грешка да се разбере колко дефекта е имало в системата и колко са открити от екипа за тестване в различни периоди на проекта. По този начин можете да получите определен среден индикатор за ефективността на екипа за тестване. Може да се декомпозира за всеки отделен тестер и да се получи лична оценка. Колкото повече опит и статистика, толкова по-малка ще бъде грешката. Можете също да използвате метода „засяване на грешки“, когато знаем точно колко грешки има в системата. Естествено, трябва да се вземат предвид допълнителни фактори, като вида на системата, сложността на логиката, платформата и т.н. Така получаваме връзката между фазата на проекта и процента на откритите дефекти. Сега можем да приложим тази зависимост в обратна посока: като знаем броя на откритите дефекти и текущата фаза на проекта, можем да определим общия брой дефекти в нашата система (с известна грешка, разбира се). И след това, въз основа на показателите на лична или обща оценка, можете да определите колко дефекта може да открие тестер или екип през оставащия период от време. Въз основа на тази оценка вече е възможно да се определи критерият за ефективност на тестера.
Функцията за индикатор за ефективност на тестера може да изглежда така:
Дефекти- броя на откритите дефекти,
Тежест– критичност на откритите дефекти,
Сложност– сложността на системната логика,
платформа– платформа за внедряване на системата,
Фаза- фаза на проекта,
месечен цикъле разглежданият период от време.
Но вече трябва да бъде избран емпирично конкретен критерий, на който трябва да отговаря един тестер, като се вземат предвид спецификите на конкретна организация.
В момента не е възможно да се вземат предвид всички фактори, но заедно с нашия водещ разработчик Иван Астафиев и ръководителя на проекта Ирина Лагер излязохме със следната формула, която отчита броя на дефектите и тяхната критичност:
 , където
, където
Е– ефективност, определена от броя на откритите дефекти,
D Клиент– броят на дефектите, открити от клиента, но които оцененият тестер би трябвало да открие,
D Тестер- броят на дефектите, открити от тестера,
кИ д– корекционни коефициенти за общия брой дефекти.
Веднага искам да отбележа, че при оценката по тази формула трябва да се вземат предвид само онези дефекти, които са свързани с областта на отговорност на оценявания тестер. Ако няколко тестери споделят отговорността за пропуснат дефект, тогава този дефект трябва да бъде включен в оценката на всеки тестер. Също така при изчислението не се вземат предвид нискокритичните дефекти.
 Така имаме парабола от трета степен, отразяваща критерия за интензивност на откриване на дефекти, на който трябва да отговаря тестера. Като цяло, ако резултатът на тестера е над параболата, това означава, че той работи по-добре от очакваното, ако е по-нисък, тогава, съответно, по-лошо.
Така имаме парабола от трета степен, отразяваща критерия за интензивност на откриване на дефекти, на който трябва да отговаря тестера. Като цяло, ако резултатът на тестера е над параболата, това означава, че той работи по-добре от очакваното, ако е по-нисък, тогава, съответно, по-лошо.
Има нюанс, свързан с общия брой анализирани дефекти. Естествено, колкото повече статистика, толкова по-добре, но понякога трябва да анализирате различните етапи на проекта, понякога просто се нуждаете от оценка за всеки период от време. И едно е, когато се открият 4 дефекта през периода и 2 от тях са от клиента, и съвсем друго, когато се открият 100 дефекта, като 50 от тях са от клиента. И в двата случая съотношението на броя на дефектите, открити от клиента и тестера, ще бъде равно на 0,5, но разбираме, че в първия случай не всичко е толкова лошо, но във втория е време да бием алармата.
След като се опитахме без особен успех да направим строго математическо обвързване с общия брой дефекти, ние прикрепихме, по думите на същата Ирина Лагер, „патерици“ към тази формула под формата на интервали, за всеки от които определихме своя собствена коефициенти. Имаше три интервала: за статистика от 1 до 20 дефекта, от 21 до 60 дефекта и за статистика за повече от 60 дефекта.
|
Брой дефекти |
к |
д |
Прогнозна допустима част от установените от клиента дефекти от общия брой открити дефекти |
Последната колона в таблицата е въведена, за да обясни колко дефекта е позволено да открие клиентът в тази извадка. Съответно, колкото по-малка е извадката, толкова по-голяма може да бъде грешката и толкова повече дефекти могат да бъдат открити от клиента. От гледна точка на функцията това означава лимитиращата минимална стойност на съотношението на броя дефекти, открити от клиента и тестера, след което ефективността става отрицателна, или точката, в която графиката пресича оста X. колкото по-малка е извадката, толкова по-правилно трябва да бъде пресечната точка с оста. От управленска гледна точка това означава, че колкото по-малка е извадката, толкова по-малко точна е такава оценка, следователно изхождаме от принципа, че тестерите трябва да бъдат по-малко стриктно оценявани на по-малка извадка.
Имаме графики в следния вид:

Черната графика отразява критерия за вземане на проба над 60 дефекта, жълта за 21-60 дефекта, зелена за вземане на проби по-малко от 20 дефекта. Вижда се, че колкото по-голяма е извадката, толкова по-вляво графиката пресича оста X. Както вече споменахме, за оценяващия служител това означава, че колкото по-голяма е извадката, толкова повече можете да се доверите на тази цифра.
Методът за оценка се състои в изчисляване на ефективността на работата на тестера съгласно формула (2), като се вземат предвид корекционните коефициенти и се сравнява тази оценка с необходимата стойност на графиката. Ако резултатът е по-висок от графиката, тестерът отговаря на очакванията; ако е по-нисък, тестерът работи под изискваната "лента". Искам също да отбележа, че всички тези цифри са избрани емпирично и за всяка организация те могат да бъдат променяни и избрани по-точно с течение на времето. Ето защо всякакви коментари (тук или в моя личен блог) и подобрения само приветствам.
Този метод на оценка чрез съотношението на броя дефекти, открити от тестовия екип и клиент/потребител/клиент ми се струва разумен и повече или по-малко обективен. Вярно е, че такава оценка може да се извърши само след завършване на проекта или поне ако има активни външни потребители на системата. Но какво ще стане, ако продуктът все още не се използва? Как да оценим работата на тестер в този случай?
В допълнение, тази техника за оценка на ефективността на тестер създава няколко допълнителни проблема:
1. Един дефект започва да се разделя на няколко по-малки.
· Мениджърът на теста, който е забелязал такава ситуация, трябва да я спре с неформални методи.
2. Управлението на дефекти става по-сложно поради нарастващия брой дублиращи се вписвания.
· Правилата за регистриране на дефекти в системата за проследяване на грешки, включително задължителен преглед на подобни дефекти, могат да помогнат за решаването на този проблем.
3. Липса на качествена оценка на откритите дефекти, тъй като единствената цел на тестера е броят на дефектите и в резултат на това липсата на мотивация у тестера да търси „качествени“ дефекти. И все пак не може да се приравнява критичността и „качеството“ на дефекта, второто е по-малко формализирано понятие.
· Тук решаваща роля трябва да играе „отношението” както на тестера, така и на мениджъра. Само общо правилно (!) разбиране на смисъла на такава количествена оценка може да реши този проблем.
Обобщавайки всичко по-горе, стигаме до заключението, че не само е трудно, но и не е напълно правилно да се оцени работата на тестер само по броя на откритите дефекти. Следователно броят на откритите дефекти трябва да бъде само един от показателите за интегралната оценка на работата на тестера, и то не в чист вид, а като се вземат предвид факторите, които изброих.







